RDSWEB | Cyber Security · OSINT · Inteligência Corporativa Falar no WhatsApp RDS WEB Início Due Diligence Invest. Defensiva Cyber Security RDSWEB · Inteligência Corporativa Proteja sua empresa antes que o próximo incidente aconteça Cyber Security · OSINT · Investigação Defensiva · Inteligência Corporativa Sua empresa está realmente preparada para enfrentar vazamentos de dados, fraudes internas, golpes digitais ou ataques cibernéticos? Todos os dias organizações perdem dinheiro, reputação e informações estratégicas por não identificarem riscos ocultos a tempo. Solicitar Consultoria Ver LinkedIn 20+ Anos de Experiência 400+ Ferramentas OSINT 100% Ética & LGPD ...
Gerar link
Facebook
X
Pinterest
E-mail
Outros aplicativos
Utilizando o Scrapy do Python para monitoramento em sites de notícias (Web Crawler)
Nem todo serviço ou páginas na internet disponibilizam acesso através de APIpara manipulação dos dados, nesses casos, uma das alternativas para coletar as informações disponíveis na web (notícias, fórum, comentários, etc) são os Web crawlers. De maneira resumida, um Web crawler é um programa que colhe conteúdo na web de forma sistematizada através do protocolo padrão da web (http/https).
Como os Web crawlers não dependem de API específica, tudo que está disponível na internet se torna passível de ser colhida.
Se está na internet, é possível coletar
Dessa forma, técnicas de Web crawlers são bastante utilizadas para diversos propósitos:
Motores de busca
Monitoramento de marcas ou assuntos em portais e notícias
Criação de banco de dados offline para processamento de conteúdo originalmente na web (imagens, vídeos, text, etc)
A maioria das linguagens de programação dão suporte a ferramentas que possibilitam a realização de Web Crawler, existem também bibliotecas específicas, como o Scrapy em Python, o crawler4j em Java, e o Mechanize e Watir que são bibliotecas Ruby.
Nesse artigo utilizaremos o Scrapy para coletar notícias, criando assim um crawler que pode ser utilizado para monitoramento de assuntos em sites de notícias.
Scrapy é um Framework open source para extração de informação em websites, ou seja, Framework para Web Crawler.
Por ser um Framework, o Scrapy disponibiliza diversas funcionalidades que facilitam o o processo de crawler. Desde o controle de navegação na web, bibliotecas de parse em HTML, representação de dados e pipelines para filtragem e tratamento de dados.
Instalando e criando projeto com Scrapy
O Scrapy é um pacote do Python e está disponível pelo pip. Pra instalar a última versão do Scrapy pelo pip o comando é :
$ pip install scrapy
Após a instalação, já é possível criar um projeto Scrapy com o comando:
$ scrapy startproject MEU_PROJETO
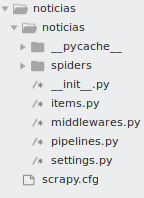
Um projeto Scrapy é composto por alguns arquivos e diretórios que estão relacionados com o fluxo de crawler pelo Framework.
Estrutura de pastas de um projeto Scrapy
Na pasta ‘/../spiders’ ficam os arquivos de spiders, onde são definidos os sites que serão utilizados no crawler, o fluxo de navegação nesses sites e como será feito o parse no html para extração da informação do crawler.
No arquivo ‘Items.py’ são definidos as classes de representação da informação. Essa é uma maneira de padronizar a informação que está sendo colhida pelo crawler. Dessa forma, mesmo usando spiders diferentes (páginas diferentes), é possível padronizar o item que está sendo colhido.
No arquivo ‘middlewares.py’ é definido como a resposta http será processada e enviada para o spider. Geralmente não é necessário modificar o middleware padrão do Scrapy, mas a depender do site que o crawler será realizado e da complexidade se torna necessário customizar o middleware.
No arquivo ‘pipelines.py’ são definidos os pipelines para processamento de cada Item. Ou seja, após o spider colher o item, o item passa por um o mais pipelines em sequência para que seja realizada alguma operação limpeza de dados, validação do item, checagem de duplicidade e se salvamento do item em um arquivo ou banco de dados.
No arquivo ‘settings.py’ está a configuração do projeto Scrapy. Nesse arquivo é possível definir a ordem de execução dos pipelines, qual middleware está habilitado, entre outras configurações.
O arquivo ‘scrapy.cfg’ é define algumas variáveis do projeto.
A documentação do Scrapy é bem completa. Demais informações podem ser encontradas em:
Uma das utilizações de Web crawler é o monitoramento de informações em sites de notícias. Dessa forma, colher as notícias é o primeiro passo para qualquer análise.
Iremos utilizar o Scrapy para coletar as notícias do site Tecnoblog, site voltado a notícias de tecnologia.
Dentro da pasta de um projeto Scrapy é possível executar alguns comandos específicos ao projeto, como criar spiders, executar o crawler.. etc
Spider
Após criar o projeto o primeiro passo é criar um spider para coletar os dados:
$ scrapy genspider Tecnoblog tecnoblog.net
O spider é responsável pelo site que será realizado o Crawler, pelo fluxo de navegação e pelo parsehtml para extração de informação. A estrutura básica de um spider é a seguinte:
O crawler começa na URL http://tecnoblog.net, que é a index com as notícias do Tecnoblog. O start_urlspode ser definido com mais de um elemento, ou seja, sites que tem urls diferentes por categoria de notícias (esportes, economia, tecnologia.. etc.), mas compartilham a mesma estrutura do html para que o parse seja igual.
A função de parse(self, response) recebe a resposta da requisição (response), que no caso é o HTML, e realiza o parse para extração da informação que está sendo colhida.
Antes de fazer a função de parse, é interessante usar algum inspector de elemento html (o firefox e o chrome têm por padrão)e o shell do Scrapy para “brincar” de buscar a informação de forma interativa.
Depois de “brincar” com a shell do scrapy e descobrir como coletar as informações necessárias, a função de parse do spider pode ser modificada para:
Dessa forma, utilizando a página inicial do http://tecnoblog.net, é possível coletar as informações de titulo, autor e link da notícia. O retorno da função de parsecom a yieldpode ser um Json ou um Item do Scrapy.
Em um projeto Scrapy podem existir diferentes spiders, em que cada spider é referente a uma fonte de crawler. Por exemplo, em nosso caso de crawler em portais de notícias, além do spider criado para o Tecnoblog, podemos criar spiders para o G1, Techtudo ou qualquer outro site de notícias, ao retornar sempre um objeto do mesmo tipo, deixamos a parte de pipelines independente do crawler.
O spider pode ser executado em standalone ou pelo framework com os demais spiders. Para executar apenas o spyper em desenvolvimento o comando é o runspider:
Dentro do log gerado pela execução do spider é possível confirmar a as informações coletadas.
Item
No arquivo items.py é possível definir a estrutura da informação que espera coletar com o crawler. Dessa forma é possível criar uma classe que representa essa informação, com atributos e métodos se necessário. Para o nosso caso, uma representação de uma notícias pode ser da seguinte forma:
Além de padronizar a informação do crawler, a utilização do Item facilita os demais métodos do framework. Ao rescrever o spider com a utilização do NoticiasItem ao invés do Json, o arquivo de spider fica da seguinte maneira:
Fluxo de Navegação
Quando falamos de fluxo de navegação de um crawler, estamos falando das páginas e sub-páginas que a spider deve visitar para colher a informação por completo. Embora realizar o crawler na página inicial traga resultados, nem sempre tem toda a informação da notícia ou mesmo todas as notícias. Para esses casos são necessários os fluxos de navegação.
O Spider pode seguir links nas páginas, da mesma forma que uma pessoa faria ao acessar o site de notícias e se deparar com a página inicial:
Acessa a página específica da notícias para coletar todas as informações, em vez de usar apenas a página de listagem.
Busca a opção de “Mais notícias” ou os “links de 1,2,3,4…30 página” que redirecionam a navegação para uma nova página com estrutura igual e noticias ainda não colhidas.
— Página especifica da notícia
No Spider podemos mudar o fluxo de navegação com a função follow, dessa forma colhemos a informação dentro da página específica da notícia. Geralmente a página de exibição da notícias requer um parse diferente, nesse caso é necessário criar uma nova função de parse (o shell do scrapy pode ajudar).
Assim o response.follow(link, parse_article) “entra” na pagina especifica da notícia e faz o parse com a função parse_article. O retorno continua sendo a nossa estrutura de notícia.
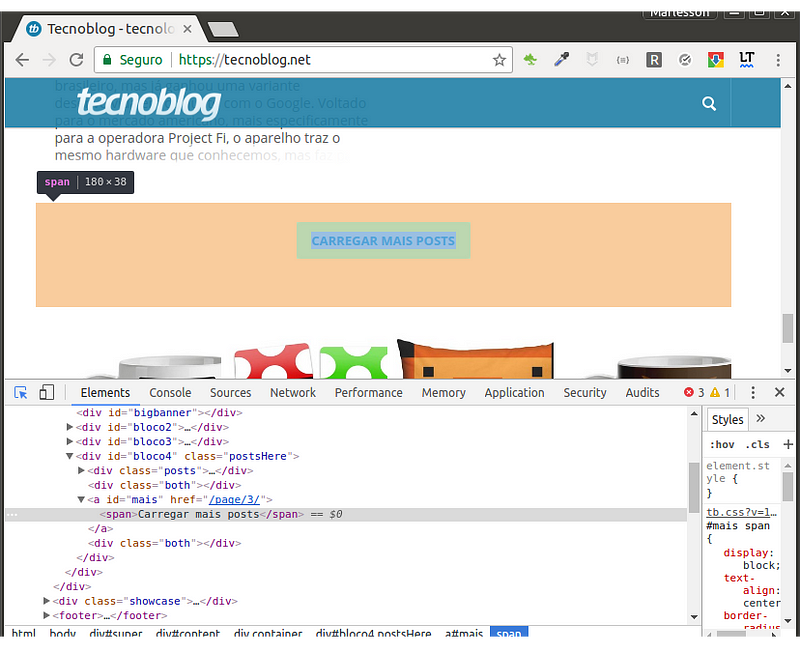
— “Mais Notícias”
A depender da necessidade do crawler se torna necessário visitar todas as páginas do site. Se o objetivo for coletar apenas as últimas notícias, a página inicial é suficiente, mas se o objetivo for coletar TODAS as notícias do site, será necessário fazer um fluxo que visite todas as páginas.
O primeiro passo é identificar os botões de “Mais Páginas”, “Numeração de Páginas” ou outros links que levem as demais páginas de notícias do site. Dessa forma é possível forçar o fluxo a percorrer todas as páginas ao localizar o link de “Mais Páginas”.
É importante que as demais páginas sigam a mesma estrutura do html, dessa forma a função de parse é a mesma e pode ser utilizada de forma recursiva.
O fluxo no Spider pode ser alterado para:
Cuidado! A depender de como a recursão é feita, além de demorar MUITO, o fluxo pode ficar preso. Geralmente se utiliza um limitador de quantidade de redirecionamentos ou itens coletados quando não for o objetivo coletar TODO o site.
Pipeline
No arquivo ‘pipelines.py’ são definidos os pipelines. Essa parte é independente do crawler e tem como principal objetivo responder a pergunta:
O que fazer com os Itens colhidos no crawler?
A resposta depende da aplicação, mas de modo geral sempre tem a ver com filtragem da informação, alteração ou limpeza e armazenamento da informação.
Um pipeline contem alguns métodos. Os métodos de open_sipder e close_spider são executados apenas uma vez, quando o spider é iniciado e quando o spider termina. Geralmente essas duas funções são utilizadas para abrir e fechar conexões com banco de dados ou arquivos.
O método process_item é executado sempre que o spider retorna um item encontrado no crawler, ou seja, para o nosso exemplo a cada notícia coletada. No método process_item que deve ser executado a filtragem, alteração ou salvamento do item no banco de dados.
— Dropando o item
No caso de querer dropar uma reportagem que tem tem autor:
— Alterando o item
Para que o autor seja colocado como upcase.
— Salvando o item em um arquivo
Para salvar o item em um arquivo ‘notices.txt’, nesse exemplo usamos a função de open_spider para abrir o arquivo, a process_item para salvar no arquivo e a close_spider para fechar o fluxo.
Diferentes pipelines podem ser empilhados, ou seja, podemos ter um pipeline para realizar a filtragem (decidir se o item é importante), outro para limpar a informação (retirando tags html se necessário) e por último um pipeline para salvar a informação no banco de dados. Dessa forma os três exemplos anteriores podem estar em pipelines diferentes.
A ordem de execução dos pipelines é definida no arquivo de configuração do Scrapy, ‘settings.py’
O Scrapy é um framework completo para Web Crawler, fácil e simples de usar. Por ser modularizado, projetos em Scrapy podem ser integrados a ferramentas de processamento de dados em strem pelo pipeline, dessa forma é possível realizar análises em tempo real.










Comentários
Postar um comentário