Raspagem sem código em 5 minutos usando planilhas do Google e Google Chrome
Conhecer a estrutura de um site é o primeiro passo para extrair e usar os dados. Vamos colocar nossos dados em uma planilha - para que possamos usá-los ainda mais. Uma maneira fácil de fazer isso é fornecida por uma fórmula especial no Google Spreadsheets.
Economize horas na agonia de copiar e colar com o comando ImportHTML no Google Spreadsheets. É realmente mágico!
Receitas
Para completar o próximo desafio, dê uma olhada no Manual em uma das seguintes receitas:
- Extração de dados de tabelas HTML .
- Raspagem usando a extensão raspadora para Chrome
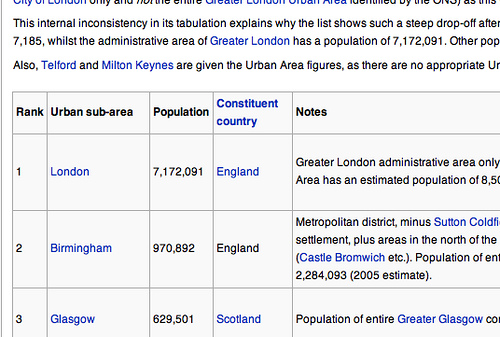
Ambos os métodos são úteis para:
- Extração de listas ou tabelas individuais de páginas da web únicas
Este último pode realizar tarefas um pouco mais complexas, como extrair informações aninhadas. Dê uma olhada na receita para mais detalhes.
Nenhum dos dois funcionará para:
- Extração de dados espalhados por várias páginas da web
Desafio
Tarefa: Encontre um site com uma tabela e extraia as informações dele. Compartilhe seu resultado em datahub.io (certifique-se de marcar seu conjunto de dados com schoolofdata.org)
Gorjeta
Depois de colocar sua tabela na planilha, você pode movê-la ou colocá-la em outra planilha. Clique com o botão direito na célula superior esquerda e selecione “colar especial” - “colar somente valores”.
Raspar mais de uma página da web: Scraperwiki
Observação: antes de prosseguir para o modo de raspagem total, é útil entender a carne e os ossos do que constitui uma página da web. Leia a introdução à receita HTML no manual.
Até agora, nós apenas extraímos dados de uma única página da web. E se houver mais? Ou você deseja raspar bancos de dados complexos? Você precisará aprender a programar - pelo menos um pouco.
Está além do escopo deste curso ensinar a raspar. Nosso objetivo aqui é ajudá-lo a entender se vale a pena investir seu tempo para aprender e apontar alguns recursos úteis para ajudá-lo em seu caminho!
Estrutura de um raspador
Raspadores são compostos por três partes principais:
- Uma fila de páginas para raspar
- Uma área para dados estruturados a serem armazenados, como um banco de dados
- Um downloader e analisador que adiciona URLs à fila e / ou informações estruturadas ao banco de dados.
Felizmente para você, existe um bom site para scrapers de programação: ScraperWiki.com

ScraperWiki tem duas funções principais: Você pode escrever scrapers - que são opcionalmente executados regularmente e os dados estão disponíveis para todos os visitantes - ou você pode solicitar que escrevam scrapers para você. Este último custa algum dinheiro - no entanto, ajuda a entrar em contato com a comunidade Scraperwiki ( Grupo do Google ), alguém pode ficar animado com o seu projeto e ajudá-lo !.
Se você estiver interessado em escrever rascunhos com o Scraperwiki, dê uma olhada neste exemplo de raspador - recolhendo alguns dados sobre o Parlamento . Clique em Exibir fonte para ver os detalhes. Verifique também a documentação do Scraperwiki: https://scraperwiki.com/docs/python/
Quando devo fazer o investimento para aprender a raspar?
Alguns motivos (lista não exaustiva!):
- Se você tem que extrair dados regularmente onde há várias tabelas em uma página.
- Se suas informações estão espalhadas por várias páginas.
- Se você deseja executar o raspador regularmente (por exemplo, se a informação é divulgada toda semana ou mês).
- Se você quiser coisas como alertas por e-mail se as informações em uma página da web em particular mudar
… E você não quer pagar ninguém para fazer isso por você!
Resumo:
Neste curso, abordamos a Web scraping e como extrair dados de sites. A principal função do scraping é converter dados semiestruturados em dados estruturados e torná-los facilmente utilizáveis para processamento posterior. Embora seja uma tarefa relativamente simples com um pouco de programação - para páginas da Web únicas também é viável sem qualquer programação. Introduzimos = importHTML e a extensão Scraper para as suas necessidades de scraping.
Última atualização em 2 de setembro de 2013.








Comentários
Postar um comentário