Converter Texto em Voz Converta seu texto em voz natural em segundos, usando mais de 630 vozes realistas. Baixe seus arquivos de áudio em formato MP3. Conversor de texto em voz Use nosso conversor de texto em voz com ajuda de vozes naturais falando 80 idiomas. Experimente gratuitamente com nossos conversores. Linguagem Africano (Sudáfrica) Albanés (Albania) Alemán (Alemania) Argelia Amárico Árabe (Asia) Árabe (Egipto) Árabe (Golfo) Árabe (Irak) Árabe (Jordania) Árabe (Kuwait) Árabe (Líbano) Árabe (Libia) Árabe (Marruecos) Árabe (Omán) Árabe (Qatar) Árabe (Arabia Saudita) Árabe (Siria) Árabe (Túnez) Árabe (Yemen) Armenio (Armenia) Azerbaiyano (Azerbaiyán) Bahréin Euskera (España) Bengalí Bengalí (India) Bosnio (Bosnia y Herzegovina) Búlgaro (Bulgaria) Birmano (Myanmar) Catalán (Esp...
Recentemente o Nubank, uma das maiores fintechs da américa latina, disponibilizou sua biblioteca de machine learning. Neste artigo, você vai aprender como fazer um pequeno modelo de classificação de sentimentos utilizando essa biblioteca, como detectar possíveis fragilidades nos dados e como avaliar a performance do modelo ao longo do tempo.
Vamos usar uma série de bibliotecas em python, tanto para análise quanto para avaliação do modelo. As principais bibliotecas que vamos usar são:
pandas
numpy
matplotlib/seaborn
nltk
statsmodels
scikit-learn
fklearn
Existem ótimos recursos online disponíveis para aprender mais sobre essas bibliotecas essenciais para o trabalho de um cientista de dados. Neste artigo o foco será no fklearn, especificamente criar um modelo de linguagem natural (NLP), explicando alguma peculiaridade ou outra sobre as bibliotecas usadas ao longo do caminho.
Ah, se quiser ir direto para o código, no final do artigo tem um link para o notebook do modelo NLP :)
1. Motivação e dataset
Existem vários datasets e exemplos na internet de modelos de análise de sentimentos de tweets. A maioria deles são conjuntos de dados bem comportados, geralmente os tweets são em inglês (que possui mais ferramentas de processamento de linguagem natural), e os dados são bem consistentes.
Porém, vamos usar um conjunto de dados que é mais próximo à nossa realidade!
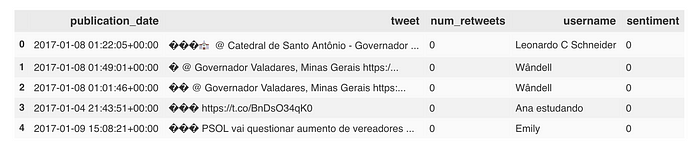
Vamos usar um dataset de tweets em português (mais especificamente relacionados ao estado de Minas Gerais), que encontrei como CSV nesse repositório do github. Fazendo o download do arquivo CSV e abrindo-o com o pandas, podemos ver a estrutura do dataset:
Estrutura do dataset original
Temos 8199 linhas (um tweet por linha), e 26 colunas. Há várias colunas sem nome, a data não está formatada, vários valores ausentes (NaNs), colunas com nome em inglês e português, enfim, o combo completo.
O nosso modelo irá usar apenas o conteúdo do tweet para tentar classificar o sentimento daquele tweet, portanto vamos nos livrar das outras colunas irrelevantes. Além disso, a coluna Classificacao tem os valores (Neutro, Negativo, Positivo). Vamos transformar em um modelo binário, apenas Negativo ou Positivo, mapeando o conteúdo neutro para uma das duas classes possíveis aleatoriamente. Abaixo faço o seguinte pré-processamento dos dados:
Renomear e selecionar apenas as colunas que serão usadas para a análise e criação do modelo
Formatar a coluna publication_date como o tipo datetime
Mapear a coluna sentiment para 0 caso a classificação original seja "Negativo", 1 para "Positivo", e distribuir o "Neutro" entre as duas classes
Processamento inicial
Dataset após limpeza
Bem melhor! Mas antes de começar a fazer o modelo, vamos fazer uma análise exploratória dos dados para entender melhor o que temos.
2. Análise Exploratória
Uma das etapas mais importantes antes de criar um modelo de machine learning é análisar os dados que temos disponíveis para a construção do modelo.
"A machine learning model is only as good as the data it is fed" — Reynold Xin
Aqui irei mostrar apenas uma parte da análise pois não é o foco. Você pode conferir outras análises feitas no jupyter notebook desse modelo, o link está no final do artigo!
Distribuição das classes
Olhando a quantidade de tweets que temos em cada classe, 0 e 1, podemos até achar que os dados estão bem comportados e equilibrados…
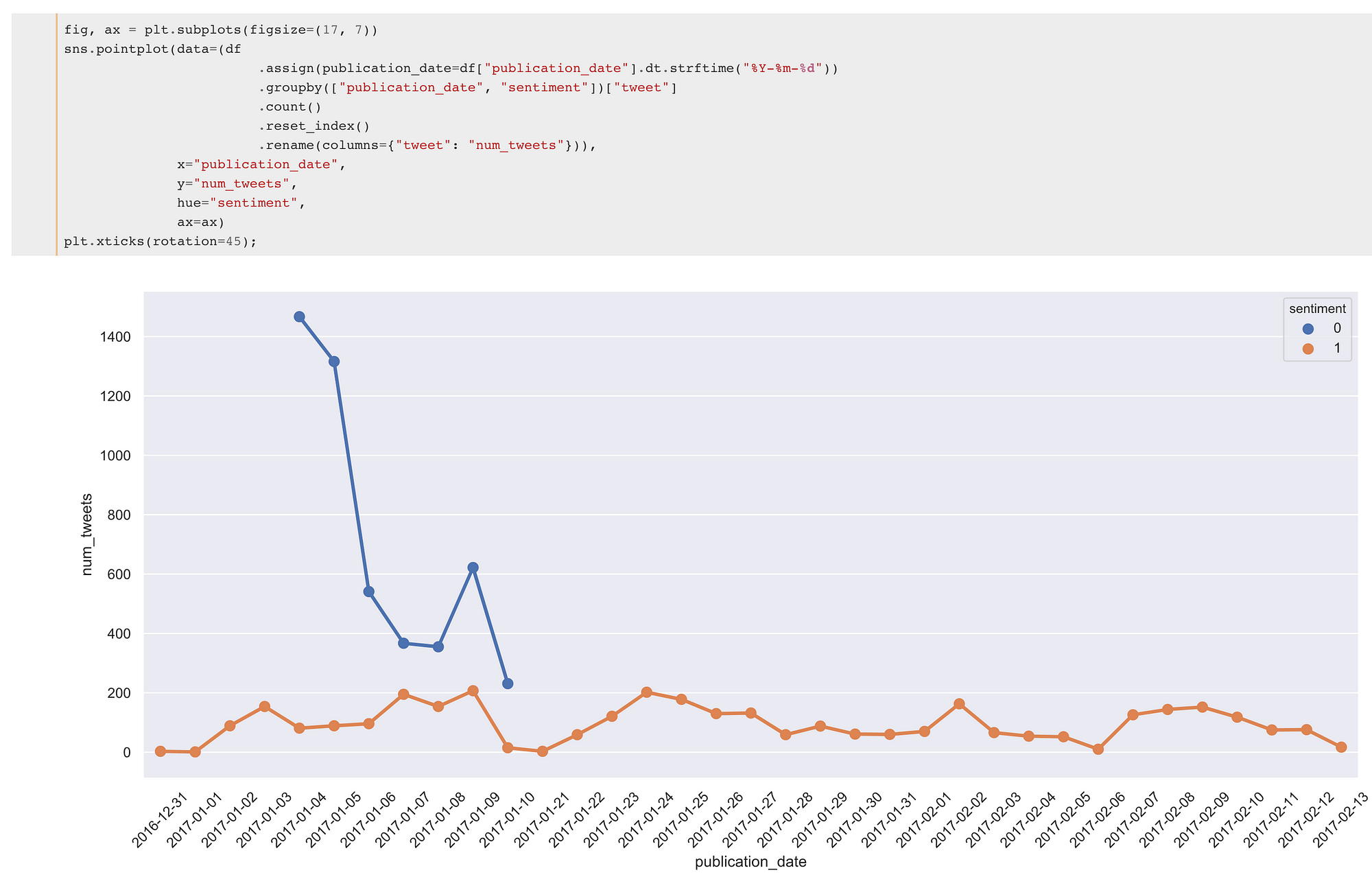
Quantidade de tweets em cada classe
Mas como em muitos datasets da vida real, aqui vemos um claro problema: A distribuição temporal dos sentimentos dos tweets é bastante diferente para as duas classes. A partir do final de janeiro de 2017, não há praticamente mais nenhum exemplo de tweet classificado como negativo.
Isso pode piorar bastante a generalização do modelo, portanto é bem importante avaliar a performance do modelo ao longo do tempo! E claro, o fklearn vai ajudar nesta tarefa.
Distribuição da quantidade de tweets e retweets
Vou aproveitar essa seção para mostrar uma ferramenta muito útil na análise exploratória mas que vejo poucas pessoas fazendo uso, a ECDF.
A ECDF é um mapeamento da função de distribuição cumulativa de um conjunto de dados, e permite obter vários insights sobre a distribuição dos seus dados de um jeito simples e rápido (se mais pessoas tiverem interesse, posso fazer um artigo sobre ela). A biblioteca statsmodels permite calcular a ECDF de um jeito bastante simples:
A ECDF de tweets por usuário dá bem mais informações sobre os dados do que um histograma. De primeira, já conseguimos observar que praticamente 95% de toda a base de usuários possui menos de 10 tweets e que há outliers de usuários com algo próximo a 300 tweets.
Já a ECDF da quantidade de retweets é um pouco diferente, embora também percebemos que cerca de 90% da base tem menos de 125 retweets, e também há outliers, o que é esperado: alguns poucos tweets viralizam e ganham muitos retweets, mas a maioria fica num intervalo de poucos retweets.
Palavras mais frequentes
Geralmente analisar as palavras mais frequentes é interessante em um modelo de NLP, e você consegue fazer isso de um jeito razoavelmente simples usando a biblioteca nltk.
Palavras mais frequentes do corpus
Neste caso não consegui ver muita coisa interessante, apenas que grande parte dos tweets estão compartilhando links, e que provavelmente o tema central dos tweets são a situação política e social do estado de Minas Gerais ou do Brasil ¯\_(ツ)_/¯
3. Criando o modelo
Há uma série de algoritmos diferentes que podemos usar para classificação de texto, desde uma simples regressão logística até os famigerados modelos de deep learning. A ideia aqui é usar um modelo clássico, e que geralmente funciona bem para classificação de texto, o modelo N-grams (N-gramas) com regressão logística.
O fklearn possui um learner que implementa esse modelo, o nlp_logistic_classification_learner . Internamente, ele utiliza o TfidfVectorizer e a LogisticRegression da biblioteca scikit-learn. Você deve passar como parâmetro as colunas do seu dataframe que contém o texto que será usado na classificação, a coluna que possui o target (aqui é a coluna sentiment ) e os parâmetros para o Tfidf e a regressão logística.
Abaixo, construímos uma função que constrói a pipeline de treino do modelo. Lembre-se: as funções do fklearn abusam de currying, prática muito usada na programação funcional.
Currying é o processo de transformar uma função que recebe múltiplos parâmetros em uma função que recebe apenas um subconjunto de parâmetros e retorna outra função se ainda há argumentos que precisam ser preenchidos
pipeline de treino
*No código acima, o log_learner_time apenas vai calcular o tempo de treinamento para nós.
Neste modelo vou usar N-grams de 1 (uma única palavra) até 3 (três palavras), remover termos com frequência muito baixa ou muito alta e usar o conjunto de stopwords da língua portuguesa disponível na biblioteca nltk.
Stopwords são palavras muito comuns de um idioma que geralmente não agregam muita informação, como por exemplo: ‘pelos’, ‘tua’, ‘houve’, ‘tinham’, ‘tem’
parâmetros do learrner
Para avaliação da performance do modelo, o fklearn já possui as principais métricas dentro do módulo fklearn.validation.evaluators . Neste modelo vou olhar as métricas AUC, LogLoss, Precision e Recall. Como falei antes, vamos olhar as métricas ao longo do tempo também, e o temporal_split_evaluator é a ferramenta feita para isso. Vamos então criar uma função de avaliação, combinando todas essas coisas:
Função de avaliação
Veja que por enquanto não passamos nenhuma informação acerca dos nossos dados para essas funções, o que permite que elas sejam isoladas, podendo servir para qualquer outro problema parecido!
4. Separação do conjunto de treino e validação
Para treinar o modelo, precisamos apenas de uma função / pipeline de treino. Após aplicar a função de treino em cima do nosso conjunto de dados, podemos aplicar a função de avaliação em cima do dataframe resultante (já com a predição do modelo) para obter as métricas.
A coluna do tempo é a publication_date e como espaço vou usar a coluna username : assim, conseguimos um conjunto de validação (holdout) que contém tweets em período depois do treino (out of time), tweets de usuários que não aparecem no treino (out of space) e tweets de usuários que não aparecem no treino e também são de um período futuro ao treino (out of time and out of space).
Separando os dados
Após fazer o split, vamos juntar o holdout em um único dataframe e verificar o tamanho do conjunto de treino e validação.
Separação entre treino e validação
5. Juntando tudo e treinando o modelo
Depois de definir todas essas funções, é bem fácil rodar o modelo :D, basta criar a função de treino e avaliação passando as informações do dataset, e aplicar em no conjunto de treino e validação.
treinando o modelo e avaliando no holdout
Essas são as variáveis importantes após o treino :
predict_function:O modelo em si, é uma função que recebe um dataframe e retorna um novo dataframe com uma coluna prediction , que é a previsão do modelo
training_scored, holdout_scored: dataframes de treino e validação, porém com a coluna prediction do modelo NLP
training_evaluation, holdout_evaluation: Dicionários com os logs das métricas
Exemplo de predição
6. Avaliando a performance do modelo NLP
Ao invés de olhar manualmente os logs (dentro dos dicionários training_evaluation e holdout_evaluation), podemos usar as funções de extração do fklearn para facilitar a visualiação desses dados, disponíveis no módulo fklearn.validation.evaluators .
Abaixo, criamos um base_extractor que irá extrair as 4 colunas com as métricas básicas utilizadas (auc, logloss, precision, recall).
Já o resultado da avaliação temporal feita está disponível nas chaves de nome “split_evaluator__publication_date_”. Para facilitar, criei a função create_year_week_extractor que mapeia todos os splits feitos e retorna um split_evaluator_extractor .
Funções para extrair os logs das métricas
Performance no treino
Aplicar o extractor que foi criado ao dicionário que contém as métricas retorna um dataframe do pandas com as métricas nas colunas:
Métricas básicas no treino
Para visualizar a métrica ao longo do tempo, vou usar a função que defini lá em cima (create_year_week_extractor ) e aplicar essa função em cima do training_evaluation. Com um pouco de mágica do pandas, podemos ver a performance das principais métricas (tirei o LogLoss porque a interpretação dessa métrica é um pouco diferente):
Métricas ao longo do tempo no treino
Performance no holdout
Faço a mesma coisa com o conjunto holdout… Ah, é importante notar que as métricas de precision e recall usam um threshold padrão de 0.5. Isto é, antes de calcular as métricas, toda predição ≥ 0.5 vai ser considerada 1, e 0 caso contrário.
Métricas básicas no holdout
Agora conseguimos ver a performance do modelo NLP ao longo do tempo no holdout, do mesmo jeito que fizemos no treino! Veja que o AUC não aparece em toda a avaliação, porque não existem mais exemplos de classe 0 depois de fevereiro de 2017.
Métricas ao longo do tempo no holdout
7. Considerações finais
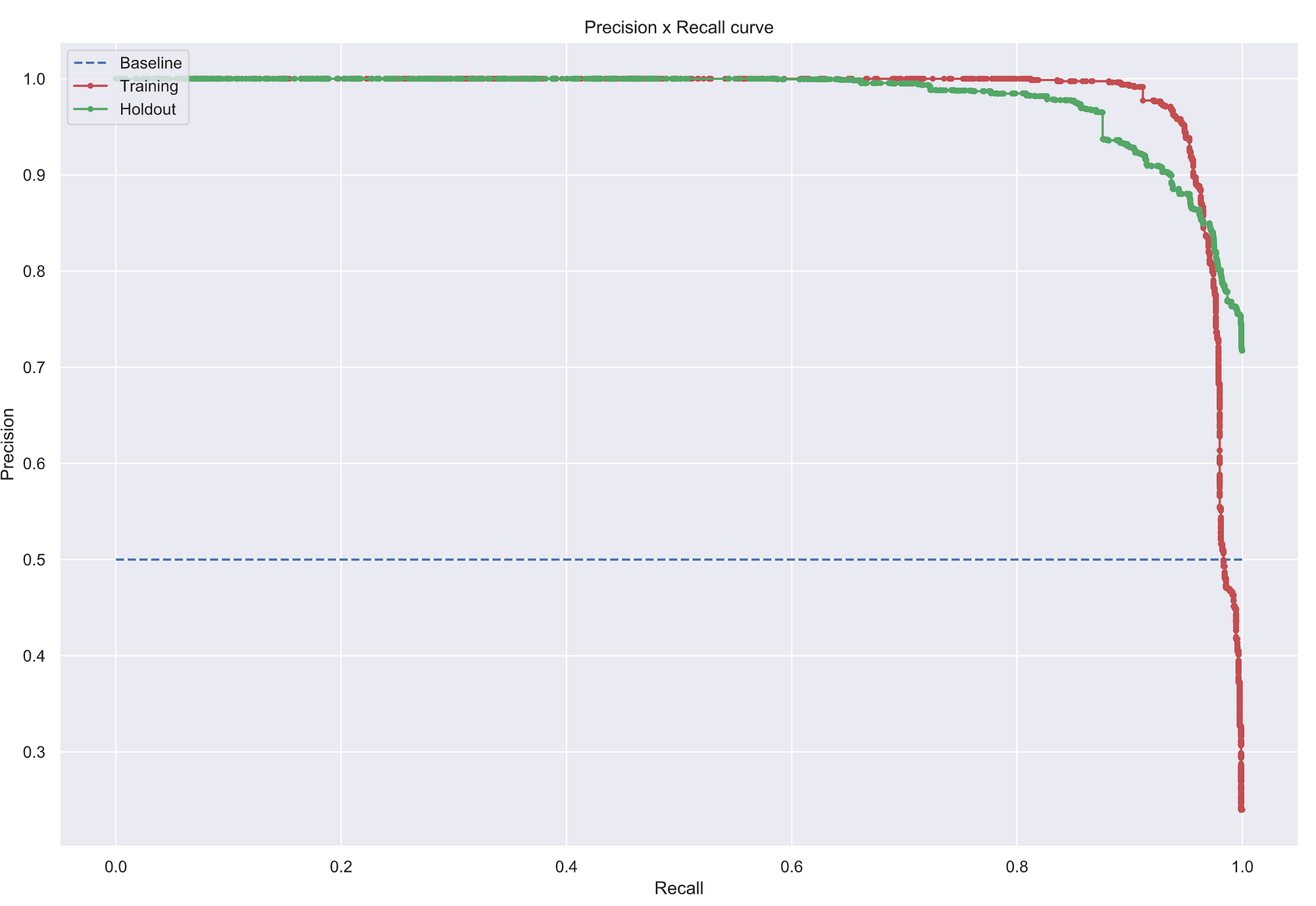
Bom, esse é o fluxo básico para a análise do modelo NLP treinado! A partir de agora, podemos tentar melhorá-lo de várias formas. Por exemplo, note como a precision no tempo fica sempre em 1, enquanto o recall varia bastante, o que sugere que talvez um threshold de 0.5 não seja o adequado.
Podemos olhar para a curva precision-recall para tentar entender o comportamento: veja que provavelmente existe um threshold que garantiria um melhor equilíbrio entre essas duas métricas.
Curva precision-recall
A partir daqui, há vários caminhos que você pode tentar para melhorar o modelo:
Fazer um tuning dos hiperparâmetros do nlp_logistic_classification_learner
treinar o modelo usando validação cruzada (em cima do conjunto de treino) e escolher um threshold adequado; Em seguida, avaliar novamente as curvas no holdout
Conseguir dados melhores dos períodos mais recentes para treino e validação, criar novas features em cima dos dados, etc.
E por hoje e só. Este é o meu primeiro artigo aqui no Medium, todo feedback (escrita, erros no código, etc.) é bem vindo, tanto por aqui quanto no meu e-mail. Quer manter contato? Me adicione no Linkedin e veja meus projetos no Github :)
Medium is an open platform where 170 million readers come to find insightful and dynamic thinking. Here, expert and undiscovered voices alike dive into the heart of any topic and bring new ideas to the surface. Learn more
If you have a story to tell, knowledge to share, or a perspective to offer — welcome home. It’s easy and free to post your thinking on any topic. Start a blog
























Comentários
Postar um comentário