CONFIDENCIAL treinamento · osint para due diligence Mural de investigação: verificação de empresas e fornecedores Metodologia estruturada em 8 etapas + limites éticos, usando só fontes públicas e legais. Marque o progresso por caso — dá pra reaplicar em cada empresa que você investigar. Empresa / fornecedor sendo investigado (opcional — deixe em branco para "metodologia geral") Abrir / criar caso reiniciar progresso deste caso ⚠ Limites éticos e legais — não são opcionais OSINT trabalha só com informação publicamente e legalmente acessível. As linhas abaixo não são "boas práticas" — são o que separa due diligence legítima de conduta que pode gerar responsabilidade civil, criminal ou reputacional pra você e pra empresa. Nunca acessar sistemas sem autorização, tentar quebrar senhas, o...
Uma das melhores maneiras de se praticar suas habilidades de Data Science e construir o seu portfólio, é trabalhando em projetos pessoais. Um dos melhores jeitos de encontrar um projeto para fazer é com algo relacionado a seus gostos pessoais, como por exemplo, algum esporte.
Para trabalhar em seu projeto, é possível utilizar a seção de datasets do Kaggle para verificar se já existe uma base do jeito que você quer. Caso não exista, é possível extraí-los do jeito que quiser de sites da Internet com o uso de técnicas de Web Scraping.
Uma boa opção para estatísticas esportivas são os sites do grupo Sports Reference. Eles trazem vários tipos de estatísticas, desde as mais simples até as avançadas sobre os mais variados esportes, como Basquete, Baseball e Futebol Americano, do universitário ao profissional das mais diferentes ligas.
Sites do grupo Sports Reference
Como exemplo, usarei o site de Basquete para extrair dados da NBA, porém com os conhecimentos deste tutorial você será capaz de extrair informações de qualquer um dos outros sites com pequenas modificações, tendo em vista que por serem da mesma empresa eles possuem o mesmo padrão.
Todo o código desse tutorial pode ser acessado nesse gist.
Bibliotecas utilizadas:
requests: biblioteca para execução de requisições HTTP;
BeautifulSoup: biblioteca para extração de dados em arquivos HTML e XML;
Pandas: biblioteca para armazenar, limpar e salvar os dados em forma de tabela.
Usaremos as bibliotecas acima da seguinte forma: Usaremos arequests para executar requisições GET e obter o código HTML das páginas que queremos; depois, utilizaremos a BeautifulSoup para extrair os dados que queremos destas páginas; por fim, salvaremos esses dados em um Data Frame do Pandas.
Extraindo tabelas de estatísticas
Como primeiro exemplo, vamos utilizar a página de Estatísticas Individuais Totais da temporada de 2017/2018 da NBA. Esta página contém uma única tabela, onde cada linha representa um jogador e as respectivas informações deles na última temporada da NBA, como por exemplo a quantidade de minutos jogados e arremessos convertidos.
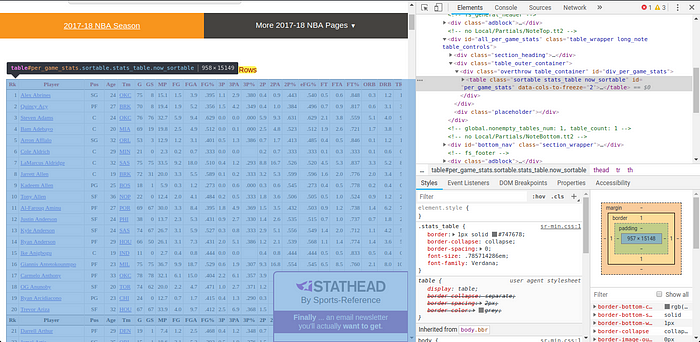
Utilizando a ferramenta de inspeção do navegador na tabela, podemos verificar que os dados estão armazenados em uma tabela HTML, representado pela tag table.
Utilizando a função Inspecionar para analisar o HTML.
Sabendo qual elemento devemos extrair da página HTML para conseguir os dados, é possível começar a parte da programação!
Primeiro, devemos importar a bibliotecas que serão usadas:
import pandas as pd import requests from bs4 import BeautifulSoup
O primeiro passo será fazer uma requisição GET para a página. Para isso, devemos chamar o método requests.get com a URL da página como argumento.
Este método retorna um objeto Response que contém vários informações, das quais utilizaremos o status_code para verificar se a requisição retornou um status 200, indicando que ela foi bem sucedida, e content para acessar o código da página HTML.
Depois de obter o HTML da página, podemos utilizar a biblioteca BeautifulSoup para extrair a tabela. Primeiro, devemos criar um objeto que irá salvar o documento de maneira estruturada de acordo com as tags, e depois podemos acessar o elemento que quisermos chamando o método find passando como argumento o nome da tag, no caso table.
Agora que temos o código HTML da tabela, podemos utilizar o Pandas para carregar os dados em um Data Frame, utilizando o método read_html. Para isto, existem dois pontos para ficar atento: o primeiro é que antes de passar a variável ‘table’ na função, devemos convertê-la para string primeiro, tendo em vista que no momento ela é um objeto do BeautifulSoup; o segundo é que o retorno deste método é sempre uma lista de Data Frames, e portanto devemos acessar a posição 0 dela para obter nossa tabela.
No caso anterior, a página continha somente uma tabela, então havia somente uma tag table para extrair. No entanto, em muitas páginas existem várias tabelas, como é o caso da página de Classificações da temporada de 2017/2018 da NBA, por exemplo. Neste caso, para obter uma tabela específica existem duas opções:
A primeira é substituir o método find pelo find_all, que retorna uma lista de todos os elementos encontrados ao invés de um só. Nesse caso, é possível acessar a tabela desejada verificando em qual posição do vetor ela se encontra.
A segunda é utilizar o argumento attrs do método find, passando um dicionário que indica quais atributos o elemento obrigatoriamente deve ter para ser extraído. Por exemplo, considerando a página de classificações citada acima e que queremos extrair as colocações dos times na conferência Oeste (Western Conference), usamos o inspetor para verificar que o id dessa tabela é “confs_standings_W”. Portanto, o código ficaria da seguinte forma:
Agora que conseguimos extrair dados de uma única página, seria interessante obter dados de várias temporadas de uma só vez. Comparando a URL de Estatísticas de 2018 com a de 2017, podemos ver que elas são iguais, com exceção do número do ano da temporada.
Com isso, é possível criar um loop que itere sobre uma lista de anos incluindo eles na URL e repetindo o processo da seção anterior para cada uma delas, montando uma grande tabela. Para obter uma lista de todos os anos em um certo intervalo, podemos usar a função range nativa do Python.
O código a seguir cria uma função que faz isso automaticamente, e usa ela para extrair as estatísticas totais de 2013 a 2018. Perceba que uma coluna Year é criada em cada extração para que seja possível diferenciar de qual ano cada estatística pertence no DataFrame principal.
def scrape_stats(base_url, year_start, year_end): years = range(year_start,year_end+1,1)
final_df = pd.DataFrame()
for year in years: print('Extraindo ano {}'.format(year)) req_url = base_url.format(year) req = requests.get(req_url) soup = BeautifulSoup(req.content, 'html.parser') table = soup.find('table', {'id':'totals_stats'}) df = pd.read_html(str(table))[0] df['Year'] = year final_df = final_df.append(df) return final_dfurl = 'https://www.basketball-reference.com/leagues/NBA_{}_totals.html'df = scrape_stats(url, 2013, 2018)
Pequeno exemplo de uso dos dados
Primeiro, algo importante a se fazer é fazer uma pequena limpeza dos dados. Olhando a tabela no site, podemos ver que os nomes das colunas se repetem várias vezes no meio dela. Podemos eliminar essas linhas do Data Frame da seguinte maneira:
drop_indexes = df[df['Rk'] == 'Rk'].index # Pega indexes onde a coluna 'Rk' possui valor 'Rk' df.drop(drop_indexes, inplace=True) # elimina os valores dos index passados da tabela
Outra coisa que tem que ser feita é converter os valores que representam números na tabela, pois quando o Panda pega a tabela do HTML, todos os dados são lidos como objetos.
Depois, é possível utilizar o Pandas em conjunto com bibliotecas comoMatplotlib eSeaborn para gerar visualizações de dados interessantes.
Por exemplo, o gráfico a seguir mostra a média de bolas de 3 pontos arremessadas por ano na NBA.
import matplotlib.pyplot as plt import seaborn as snssns.barplot(x=’Year’, y=’3PA’)
Gráfico de média de tentativas de arremessos de 3 pontos por temporada
Perceba como o número de bolas de 3 arremessadas aumentou consideravelmente nos últimos anos, indo de aproximadamente 90 para 120 entre 2013 e 2017, aonde atingiu uma estabilidade. Podemos concluir que nos últimos anos esse tipo de arremesso passou a ter cada vez mais importância no jogo.
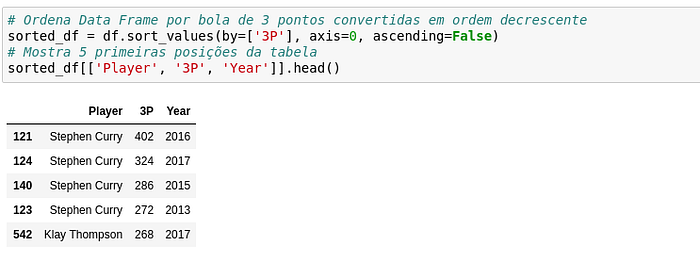
Já que o volume de bolas de 3 aumentou consideravelmente, quais são os jogadores que mais acertaram nesse período? Vamos verificar o top 5 de arremessadores com manipulações do Pandas.
Gerando tabela de maiores números de arremessos de 3 pontos convertidos
Uau! O jogador Stephen Curry, da equipe do Golden State Warriors, ocupa 4 das 5 primeiras posições do top 5, seguido de seu companheiro de equipe Klay Thompson! Não é a toa que ele já é considerado um dos melhores arremessadores da história, e que seu time ganhou 3 dos 6 campeonatos disputados nesse período, além de uma campanha histórica de 73 vitórias e somente 9 derrotas na Temporada Regular!
E se somarmos todas as bolas de 3 convertidas por jogadores nesse período, como ficaria o top 5?
Gerando tabela de soma de arremessos dados e convertidos dos últimos 5 anos
Podemos ver que Curry lidera com uma boa folga do segundo colocado, James Harden, e com uma quantidade menor de arremessos, o que mostra que ele foi mais eficiente do que Harden. Além disso, podemos ver que tanto Curry quanto Harden arremessam muito mais bolas de 3 comparado aos outros jogadores no top 5.
Concluindo
Espero que este tutorial tenha te ajudado a entender como funciona o processo de Web Scraping e te inspire a começar seus projetos pessoais de Data Science sobre seu esporte favorito!
Além de gerar várias visualizações de Dados interessantes, outra possibilidade seria gerar modelos de Machine Learning, para prever:
qual time tem mais chances de ser campeão;
quais serão os Novatos com maior evolução com base nos dados históricos;
comparar jogadores de diferentes períodos de acordo com seu estilo de jogo;
quem será o melhor jogador da temporada (Prêmio de MVP).
Caso tenha alguma sugestão ou dúvida, fique a vontade para comentar ou me adicionar no LinkedIn para conversar sobre o artigo.



















Comentários
Postar um comentário