Tiktokio – Baixe vídeos do TikTok Sem marca d'água Gratuito (2026) O Tiktokio é um programa gratuito para baixar vídeos do TikTok, baseado em navegador, que salva qualquer vídeo público do TikTok como um arquivo MP4 ou MP3 limpo — sem marca d'água, sem necessidade de conta ou instalação de aplicativo. Cole o link, toque em "Baixar" e seu arquivo estará pronto em segundos. As pessoas procuram por essa ferramenta com vários nomes: tiktokio , tiktokio.com , tiktokkio , tik tokio , tiktok kio , tiktok io e sss tiktok . Todas as variações levam ao mesmo lugar: o downloader de vídeos do TikTok mais rápido e sem marca d'água disponível em 2026. Este guia abrange tudo: como usar o TikTok no Android, iPhone e PC; como extrair áudio MP3 de qualquer vídeo do TikTok; como baixar stories, apresentações de slides e fotos; solução de problemas comuns; e diretrizes de uso responsável. Seja com dois ou vinte minutos disp...
Gerar link
Facebook
X
Pinterest
E-mail
Outros aplicativos
Como extrair tweets do Twitter
Como extrair tweets do Twitter
UM TUTORIAL BÁSICO DE RASPAGEM DO TWITTER
Como extrair tweets do Twitter
Uma introdução rápida para copiar tweets do Twitter usando Python
A mídia social pode ser uma mina de ouro de dados em relação ao sentimento do consumidor. Plataformas como o Twitter se prestam a reter informações úteis, pois os usuários podem postar opiniões não filtradas que podem ser recuperadas com facilidade. Combinar isso com outras informações internas da empresa pode ajudar a fornecer uma visão sobre o sentimento geral que as pessoas podem ter em relação a empresas, produtos, etc.
Este tutorial pretende ser uma introdução rápida e direta para extrair tweets do Twitter em Python usando a API do Twitter do Tweepy ou GetOldTweets3 de Dmitry Mottl. Para fornecer orientação para este tutorial, decidi me concentrar em explorar dois caminhos: copiar tweets de um usuário específico e raspar tweets de uma pesquisa de texto geral.
Devido ao interesse em uma solução sem codificação para scraping tweets, minha equipe está criando um aplicativo para atender a essa necessidade. Sim, isso significa que você não precisa codificar para extrair dados! Estamos planejando ter um Alpha disponível até o final de 2020. Se você deseja receber atualizações ou ser contatado quando estiver disponível, inscreva-se em nossa lista de correspondência abaixo!
Tweepy vs GetOldTweets3
Tweepy
Antes de chegarmos ao scraping real, é importante entender o que essas duas bibliotecas oferecem, portanto, vamos analisar as diferenças entre as duas para ajudá-lo a decidir qual usar.
Tweepy é uma biblioteca Python para acessar a API do Twitter. Existem vários tipos e níveis diferentes de acesso à API que o Tweepy oferece, conforme mostrado aqui , mas esses são para casos de uso muito específicos. O Tweepy é capaz de realizar várias tarefas além de apenas consultar tweets, conforme mostrado na imagem a seguir. Por uma questão de relevância, vamos nos concentrar apenas em usar essa API para copiar tweets.
Lista de várias funcionalidades oferecidas por meio da API padrão do Tweepy.
Existem limitações no uso do Tweepy para copiar tweets. A API padrão só permite que você recupere tweets até 7 dias atrás e é limitada a 18.000 tweets em uma janela de 15 minutos. No entanto, é possível aumentar esse limite conforme mostrado aqui . Além disso, usando o Tweepy, você só pode retornar até 3.200 dos tweets mais recentes de um usuário. Usar Tweepy é ótimo para quem está tentando fazer uso de outras funcionalidades do Twitter, fazendo consultas complexas, ou quer as informações mais extensas fornecidas para cada tweet.
GetOldTweets3
GetOldTweets3 foi criado por Dmitry Mottl e é um fork de melhoria do GetOldTweets-python de Jefferson Henrqiue. Ele não oferece nenhuma das outras funcionalidades do Tweepy, mas se concentra apenas na consulta de tweets e não tem as mesmas limitações de pesquisa do Tweepy. Este pacote permite que você recupere uma grande quantidade de tweets e tweets com mais de uma semana. No entanto, ele não fornece a extensão das informações que o Tweepy possui. A imagem abaixo mostra todas as informações que podem ser recuperadas dos tweets usando este pacote. Também é importante notar que, a partir de agora, há um problema aberto com o acesso aos dados geográficos de um tweet usando GetOldTweets3.
Lista de informações que podem ser recuperadas no objeto de tweet de GetOldTweet3.
Usar GetOldTweets3 é uma ótima opção para alguém que está procurando uma maneira rápida e simples de fazer scraps ou quer contornar as limitações de pesquisa padrão da API Tweepy para retirar uma quantidade maior de tweets ou tweets com mais de uma semana.
Embora se concentrem em coisas muito diferentes, as duas opções são provavelmente suficientes para a maior parte do que a maioria das pessoas normalmente busca. Só depois de fazer uma raspagem com propósitos específicos em mente é que se deve realmente escolher entre usar uma das opções.
Tudo bem, chega de explicações. Este é um tutorial de raspagem, então vamos pular para a codificação.
ATUALIZAÇÃO: escrevi um artigo de acompanhamento que faz um mergulho mais profundo em como obter mais informações de tuítes, como informações do usuário, e refinar as consultas de tuítes, como procurar por tuítes por localização. Se você ler esta seção e decidir que precisa de mais, meu artigo de acompanhamento está disponível aqui .
Os Jupyter Notebooks para a seção a seguir estão disponíveis em meu GitHub aqui . Criei funções para exportar arquivos CSV a partir dessas consultas de exemplo.
Raspar com Tweepy
Existem duas partes para fazer o scraping com o Tweepy porque ele requer credenciais de desenvolvedor do Twitter. Se você já tem credenciais de um projeto anterior, pode ignorar esta seção.
Obtendo credenciais para Tweepy
Para receber credenciais, você deve se inscrever para se tornar um desenvolvedor do Twitter aqui . Isso requer que você tenha uma conta no Twitter. O aplicativo fará várias perguntas sobre que tipo de trabalho você deseja fazer. Não se preocupe, esses detalhes não precisam ser extensos e o processo é relativamente fácil.
Página de destino do desenvolvedor do Twitter.
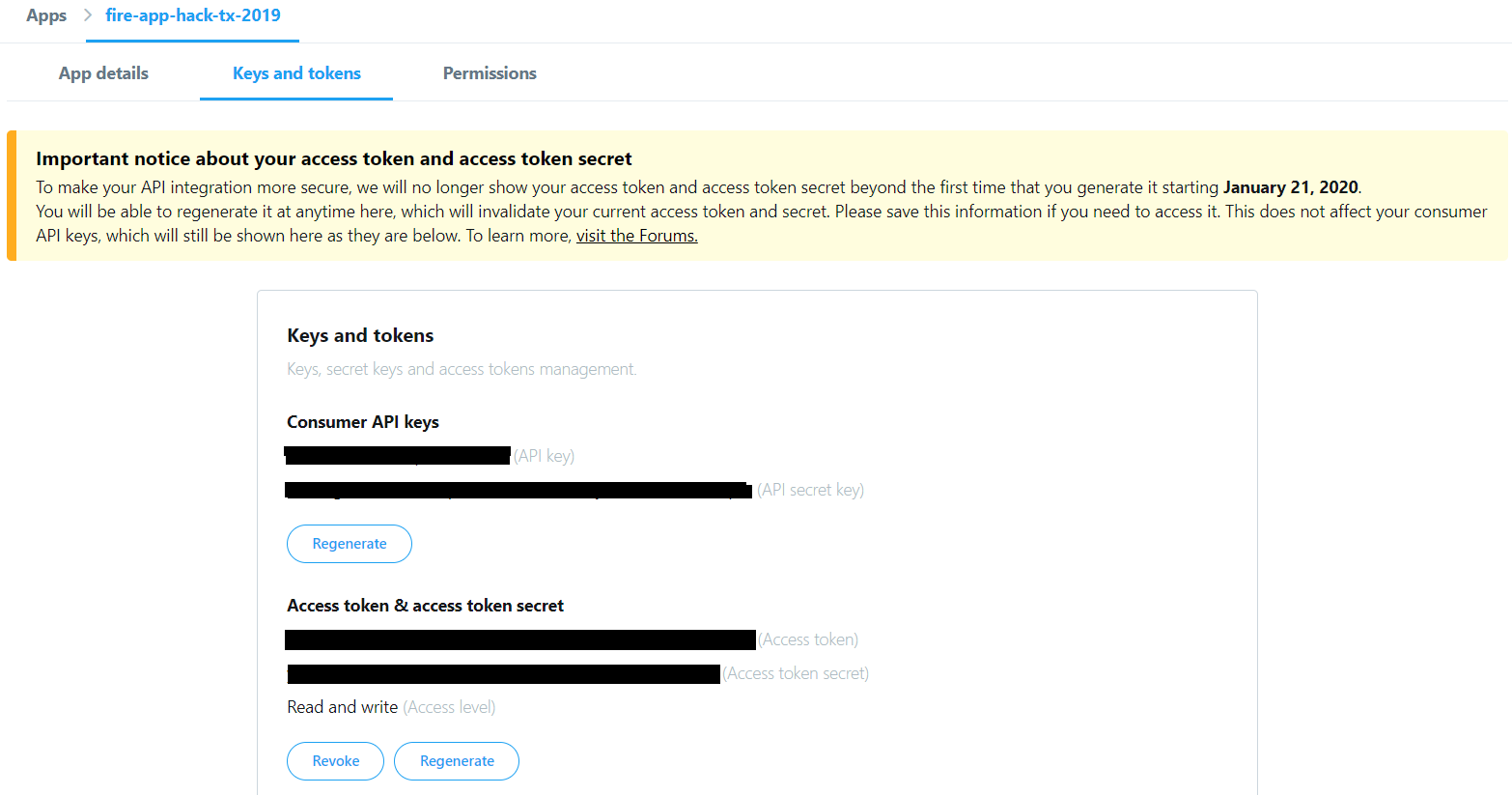
Depois de terminar o aplicativo, o processo de aprovação é relativamente rápido e não deve demorar mais do que alguns dias. Após ser aprovado, você precisará fazer login e configurar um ambiente de desenvolvimento no painel do desenvolvedor e visualizar os detalhes desse aplicativo para recuperar suas credenciais de desenvolvedor, conforme mostrado na imagem abaixo. A menos que você especificamente tenha solicitado acesso às outras APIs oferecidas, agora você poderá usar a API Tweepy padrão.
Credenciais de desenvolvedor Tweepy.
Raspagem com Tweepy
Ótimo, você tem suas credenciais de desenvolvedor do Twitter e pode finalmente começar a eliminar alguns tweets.
Configurando a autorização Tweepy:
Antes de começar, você Tweepy terá que autorizar que possui as credenciais para utilizar sua API. O fragmento de código a seguir é como alguém se autoriza.
Extrair Tweets de um usuário específico do Twitter:
Os parâmetros de pesquisa em que me concentrei são id e count. Id é o nome de usuário @ do usuário específico do Twitter e a contagem é a quantidade máxima de tweets mais recentes que você deseja extrair da linha do tempo do usuário específico. Neste exemplo, uso o nome de usuário @jack do CEO do Twitter e escolhi copiar 100 de seus tweets mais recentes. A maior parte do código de raspagem é relativamente rápido e direto.
username = 'jack' count = 150try: # Criação de método de consulta usando parâmetros tweets = tweepy.Cursor (api.user_timeline, id = username) .items (count)
# Puxando informações de tweets objeto iterável tweets_list = [[tweet.created_at, tweet.id, tweet.text ] para tweet em tweets]
# Criação de dataframe da lista de tweets # Adicionar ou remover colunas conforme você remove informações de tweet tweets_df = pd.DataFrame (tweets_list)exceto BaseException como e: print ('falhou on_status,', str (e)) time.sleep (3)
Se você deseja personalizar ainda mais sua pesquisa, pode visualizar o restante dos parâmetros de pesquisa disponíveis no método api.user_timeline aqui .
Extração de tweets de uma consulta de pesquisa de texto:
Os parâmetros de pesquisa em que me concentrei são q e count. q deve ser a consulta de pesquisa de texto com a qual você deseja pesquisar e a contagem é novamente a quantidade máxima de tweets mais recentes que você deseja extrair dessa consulta de pesquisa específica. Neste exemplo, eu analiso os 100 tweets mais recentes que foram relevantes para a eleição de 2020 nos EUA.
text_query = contagem 'Eleições dos EUA de 2020' = 150try: # Criação de método de consulta usando parâmetros tweets = tweepy.Cursor (api.search, q = text_query) .items (contagem)
# Puxando informações de tweets objeto iterável tweets_list = [[tweet.created_at, tweet.id, tweet.text ] para tweet em tweets]
# Criação de dataframe da lista de tweets # Adicionar ou remover colunas conforme você remove informações de tweet tweets_df = pd.DataFrame (tweets_list)
exceto BaseException como e: print ('falhou on_status,', str (e)) tempo .sono (3)
Se você deseja personalizar ainda mais sua pesquisa, pode visualizar o restante dos parâmetros de pesquisa disponíveis no método api.search aqui.
Que outras informações do tweet estão acessíveis?
Uma das vantagens de consultar com Tweepy é a quantidade de informações contidas no objeto de tweet. Se você estiver interessado em obter outras informações além das que escolhi neste tutorial, você pode ver a lista completa de informações disponíveis no objeto de tweet do Tweepy aqui . Para mostrar como é fácil obter mais informações, no exemplo a seguir criei uma lista de tweets com as seguintes informações: quando foi criado, o id do tweet, o texto do tweet, o usuário ao qual o tweet está associado e a quantos favoritos que o tweet tinha no momento em que foi recuperado.
tweets = tweepy.Cursor (api.search, q = text_query) .items (contagem)# Puxando informações de tweets iterável tweets_list = [[tweet.created_at, tweet.id, tweet.text, tweet.user, tweet.favorite_count] para tweet em tweets]# Criação de dataframe da lista de tweets tweets_df = pd.DataFrame (tweets_list)
Raspagem com GetOldTweets3
PROBLEMA CONTÍNUO: GETOLDTWEETS3 E ALGUNS OUTROS SCRAPERS ESTÃO ATUALMENTE EXECUTANDO EM 404 ERROS AO SCRAPING. ESTE É UM PROBLEMA CONTÍNUO E ESPERA ATUALIZAÇÕES DA BIBLIOTECA DE PYTHON. Tweepy não tem este problema atualmente: https://github.com/Mottl/GetOldTweets3/issues/98
Usar GetOldTweets3 não requer nenhuma autorização como o Tweepy requer, você só precisa instalar a biblioteca pip e pode começar imediatamente.



















Comentários
Postar um comentário