É com enorme gratidão que celebramos mais de 277 mil de audiência no blog e nas nossas interações com empresas pelo Google Maps. Cada visualização, comentário e contribuição fortalece nossa missão de unir Customer Experience, Marketing Digital e Cyber Security em soluções inovadoras e de impacto. Com mais de 5.7 mil contribuições no Local Guide, 26 mil pontos acumulados e +11 milhões de visualizações em fotos publicadas, seguimos construindo autoridade e confiança no ambiente digital. Nos colocamos à disposição para mentorias e para integrar equipes de marketing digital com foco em segurança cibernética, trazendo nossa experiência prática e resultados comprovados. 📌 Contato direto: @rdsweb 47 98861-8255 With immense gratitude, we celebrate more than 277,000 in audience on our blog and through our interactions with companies on Google Maps. Every view, comment, and contribution strengthens our mission to unite Customer Experience, Digital Marketing, and Cyber Security into innovat...
Gerar link
Facebook
X
Pinterest
E-mail
Outros aplicativos
How I Eat For Free in NYC Using Python, Automation, Artificial Intelligence, and Instagram
Living and working in the big apple comes with big rent.
I, along with most other city-dwellers who live inside a crammed closet we call an apartment, look to cut costs anywhere we can. It’s no secret one way to curtail expenses, at least we’re told, is to cook at home instead of eating out all of the time. As a Hell’s Kitchen resident this is near impossible. Everywhere I look there is a sushi bar, Mexican restaurant or some delicious looking pizzeria within arm’s length that can break my willpower in the blink of an eye. I fall victim to this way more than I’d like to admit. Well, I used to fall victim to this — until recently. Not wanting to give up the dining experiences I enjoyed so dearly, I decided I’d create my own currency to finance these transactions. I’ve been dining at restaurants, sandwich shops, and other eateries for free ever since.
I’m going to explain to you how I’m receiving these free meals from some of the best eateries in New York City. I’ll admit — it’s rather technical and not everyone can reproduce my methodology. You’ll either need a background in Data Science/Software Development or a lot of free time on your hands. Since I have the prior, I sit back and let my code do the work for me. Oh, and you guessed it, you’ll need to know how to use Instagram as well.
If you’re part of the technical audience, I will briefly go over some of the technologies and programming languages I use but I will not be providing code or anything like that. I will explain my use of logistic regression, random forests, AWS, and automation — but not in depth. If you’re a non-technical reader, everything here can still be done, it’s just going to take some time and effort. These methods are tedious which is why I decided to automate most of them.
Now to get into it. I’ll start with the answer and then go through how I got there.
What I did
In today’s digital age, a large Instagram audience is considered a valuable currency. I had also heard through the grapevine that I could monetize a large following — or in my desired case — use it to have my meals paid for. So I did just that.
I created an Instagram page that showcased pictures of New York City’s skylines, iconic spots, elegant skyscrapers — you name it. The page has amassed a following of over 25,000 users in the NYC area and it’s still rapidly growing.
I reach out restaurants in the area either via Instagram’s direct messaging or email and offer to post a positive review in return for a free entree or at least a discount. Almost every restaurant I’ve messaged came back at me with a compensated meal or a gift card. Most places have an allocated marketing budget for these types of things so they were happy to offer me a free dining experience in exchange for a promotion. I’ve ended up giving some of these meals away to my friends and family because at times I had too many queued up to use myself.
The beauty of this all is that I automated the whole thing. And I mean 100% of it. I wrote code that finds these pictures or videos, makes a caption, adds hashtags, credits where the picture or video comes from, weeds out bad or spammy posts, posts them, follows and unfollows users, likes pictures, monitors my inbox, and most importantly — both direct messages and emails restaurants about a potential promotion. Since its inception, I haven’t even really logged into the account. I spend zero time on it. It’s essentially a robot that operates like a human, but the average viewer can’t tell the difference. And as the programmer, I get to sit back and admire its (and my) work.
How I Did It
I’ll walk you through how I did what I did, from A all the way to Z. Some of this may seem like common sense, but when you’re automating a system to act like a human, details are important. The process can be broken down into three phases: content sharing, growth hacking, and sales & promotion.
The Content
Now, none of the content my account posts is owned by me. I re-share other peoples content on my page, with credit to them. If someone asks me to take down their photo, I do immediately. But since I am sourcing their page, I’ve only been thanked — never the opposite.
EDIT: I have since changed my methodology since its conception. Instead of scraping and resharing other content from Instagram. I scrape free stock photos on the internet that do not require royalty fees.
Posting every day — multiple times a day — is indispensable. This is one of the main factors the Instagram algorithm uses to determine how much they are going to expose you to the public (via the “explore page”). Posting every day, especially at “rush hour” times, is much harder and more monotonous than you might think. Most people give up on this task after a few weeks, and even missing a day or two can be detrimental. So, I automated the content collecting and sharing process.
Getting pictures and videos in inventory
I first thought about setting up a picture scraper from Google Images or from Reddit to get my content. One of the biggest struggles I came across was how particular Instagram is with the sizing of the picture being posted. Ideally, it’s a “square” picture, meaning its width equals its height, so it will reject an out-of-proportion post attempt. This made retrieving content very challenging.
I ultimately decided to scrape directly from Instagram feeds because the picture will come in precisely the right size as it is. It also allows me to know exactly where the picture came from, which will come in handy during the auto-crediting process.
I collected a list of fifty other Instagram accounts that posted quality pictures of NYC. Using some opensource software, I set up a scraper to go through and download media from these other accounts. In addition to the actual content, I scraped a list of metadata along with the picture such as the caption, the number of likes, and the location. I set the scraper to run every morning at 3:00 AM or when my inventory was empty.
From this, I now have a central location with related content in the right format.
Automatically deciding what’s “good” or “bad” content
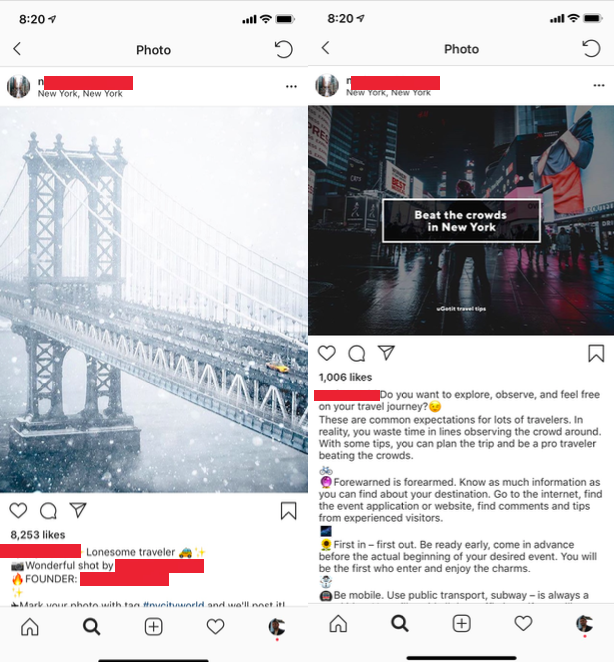
Noteverything someone posts on Instagram is re-sharable. A lot of the time people are trying to sell something, shouting another page, or it could flat out just be bad or unrelated content. Take these two posts as an example:
The above two posts are from an account called @nycityworld. The one on the left is a normal natural post in their niche — one I would be happy re-sharing on my page. The one on the right, however, is an advertisement. Without any context, if I put this on my page it would be rather confusing and out of place. The caption got cut off, but it’s actually promoting a NYC-based app. You can see the difference in the number of likes — 8200 vs. 1000. I need to be able to automatically weed out posts like those on the right, and re-share posts like that of the left.
Therefore, I can’t just blindly re-share all the content that I scrape. And since this will be an automated process, I needed to create an algorithm that can weed out the bad from the good. The first part of my “cleaner” has some hard-coded rules and the second is a machine learning model that refines the content even further.
Cleaner Part 1 — Hard Coded Rules:
The first thing I did was refine my inventory on some specific guidelines from the metadata. I was rather strict because there is no shortage of content for me to share. If there was even a slight red-flag, I trashed the picture. I can always scrape more content, but if my algorithm posts something spammy or inappropriate to my page there may be thousands of people that see it before I recognize and remove it.
The preliminary step was to have my algorithm look at the caption. If the text includes any text related to “link in bio”, “buy now”, “limited time”, or the related, I immediately have it fail the test. These are typical of posts looking to sell something rather than quality content for entertainment purposes.
The next thing I looked at is if the comments were disabled. If they were, I failed the picture. Disabled comments from my experience were linked to controversial posts and not worth the risk.
The final thing I looked at was if there was more than one person tagged in the picture. A lot of the times, one tag in a picture is a credit to where it came from, so I actually found that to be beneficial. But if the picture had multiple tags, It would lead to confusion when it came to crediting or what the purpose of the post even was.
From these rules, I was able to get most of the spammy and undesirable posts into the trash and out of my folder. However, just because a post isn’t trying to sell something doesn’t mean it’s a good, quality post. Also, my hard-coded rules may still miss some sales-y content, so I wanted to run them through a secondary model once I was done with part one.
Cleaner Part 2— Machine Learning Model:
As I was going through my now-cleaner repository of pictures, I noticed there were still some lingering items that weren’t particularly desirable to post. I wasn’t going to be able to sit there and manually move out the bad ones as I planned for this to be completely automated. I wanted to run each through another test.
I had a ton of metadata on each of the posts, including the number of likes, captions, time of post, and much more. My original goal was to try to predict which pictures would garner the most likes. However, the issue was that bigger accounts naturally had more likes so it wasn’t a fair barometer. My follow-up thought would be to make the response variable equal to the like ratio (number of likes/number of followers) and try to predict that. After looking at each picture and its respective ratio, I still didn’t trust the correlation. I didn’t feel those with higher ratios were necessarily the best photos. Just because an account was “popular” didn’t mean it had better content than a relatively unknown photographer with fewer likes. I decided to change my outlook from a regression model to a classification model and just decide if the picture is good enough to post or not — a simple yes or no.
Before even looking at any of the other metadata, I scraped a large number of photos and manually went through them, labeling them as 0 (bad) or 1 (good). This is extremely subjective, so I’m theoretically making a model to my own conscious. However, it seems to be pretty universally agreed upon as to which content is unappealing and which is favorable.
I generated my own dataset. The response variable was 0/1 (bad/good) with a large number of features. The metadata of each post gave me the following information:
Caption
Number of likes
Number of comments
Picture or video
Video views (if applicable)
When the picture was posted
Number of followers of the account that posted it
From these seven explanatory variables, I engineered a few more features that I thought would be useful. For example, I changed the number of comments and likes to ratios against followers. I extracted the number of hashtags from the caption and made that its own column, and did the same with the number of accounts mentioned in the caption. I cleaned up and vectorized the rest of the caption to be used in Natural Language Processing. Vectorizing is the process of removing peripheral words (“the”, “and”, etc.) and converting the remaining into a numeric field that can be analyzed mathematically. After all was said and done, I had the resulting data:
Response Variable:
Post Rating (0/1)
Explanatory Variables:
Vectorized caption
Number of mentions
Number of hashtags
Caption length
If the caption was edited from its origin
Media type
Video view ratio/number of days since it was posted
Like ratio/number of days since it was posted
Comment ratio/number of days since it was posted
I played around with a number of classification algorithms such as Support Vector Machines and Random Forests but landed on a basic Logistic Regression. I did this for a few reasons, first being Occam’s Razor — sometimes the simplest answer is the right one. No matter which way I spun or re-engineered the data, logistic regression performed the best on my test set. The second and more important reason was that, unlike most classification algorithms, I can set a threshold score while making predictions. It’s common for classification algorithms to output a binary class (in my case 0 or 1) but logistic regression actually yields a decimal between 0 and 1. For example, it may rate a post as 0.83 or 0.12. It’s common to set the threshold at 0.5 and rank everything greater than that to 1 and everything else to 0, but it would be case dependent. Since this task is critical, and there is an abundance of media available, I was extremely strict on my threshold and set it to 0.9 and rejected anything that fell below that benchmark.
After I implemented my model, the inventory of pictures and videos was A) cleaned by a hard set of rules and then B) only the cream of the crop was chosen by my logistic regression algorithm. I am now able to move on to captioning and crediting each post.
Auto-Captioning and Auto-Crediting
I now had a system of automatically gathering relevant content and removing the tangential or spammy images— but I’m not done yet.
If you’ve used Instagram before, you know that each post has a caption that exists under the picture or video. Being that I can’t actually see these pictures, nor do I have the time to sit there and caption them all, I needed to make a generic caption that can be used for any of them.
The first thing I did was make a final template. It looked something like this:
Where the three sets of {}’s needed to be filled in by my script. Let’s go through each three one-by-one.
Caption
I created a text file with a number of predefined generic captions that could go with any picture. These were either quotes about NYC, broad questions, or just basic praise. Some of these included:
Who can name this spot?
Tell us your favorite bar in NYC in the comments!
"You haven't lived until you've died in New York"
For each post, one of my captions was randomly chosen. I have such a large list that I’m not worried about them being used too often or overlapping. So, for our example, let’s pick the first one — “Who can name this spot?”.
2. Credit
This was one of the harder tasks — automatically crediting the source. What was particularly tricky was that the Instagram page that the media came from wasn’t necessarily the right person to credit. Often, that account was also re-sharing the content and crediting the owner in their caption or tagging them in the photo.
I decided I would credit the page where it came from no matter what. I would then add more credits if I could possibly decipher the original owner as well. I felt I would cover all of my bases this way.
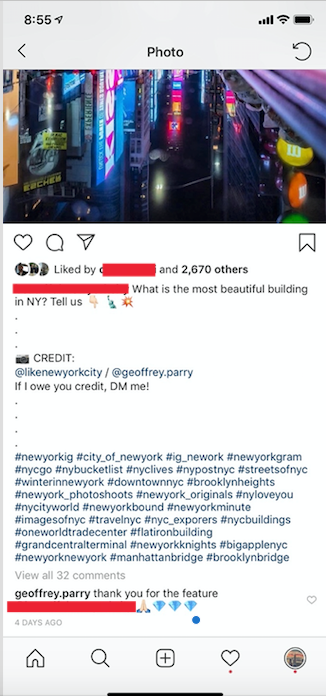
Let’s take a look at this post by @likenewyorkcity on Instagram. We can see that even though he or she was the one who shared it, the real owner is @geoffrey.parry who is tagged in the picture and mentioned in the caption.
Ideally, I would like my code to be able to look at this picture and return:
Credit: @likenewyorkcity/@geoffrey.parry
The first part of that is easy; just inputting which account it came from. The second part was a little more challenging.
I used REGEX to look for a number of keywords such as “by” or “photo:” and then look for the “@” symbol that followed right after. From there, I grabbed the username and believed that to be the second part of my credit.
If none of those keywords existed in the caption, I checked if there was anyone tagged in the picture. If there was, I figured they deserved the credit. I understand this is an imperfect method, but more times than not that’s why someone was tagged and it was a risk worth taking.
I very often capture exactly the right credit. In fact, many times I’ve had people comment on my pictures and say “thank you for sharing!” (I’ve added an example of that below).
3. Hashtags
Instagram allows you to add 30 hashtags to your picture which will then be displayed on that hashtag’s feed. I created a file with over 100 related hashes:
and randomly chose 30 to add each time. I did that so after a while, I can compare which hashtags lead me to a greater number of likes.
4. Final Template
After the three steps were said and done, I was able to fill in my template and have a caption that can go along with any post.
Who can name this spot?
.
.
.
Credit: @likenewyorkcity/@geoffrey.parry
.
.
.
#newyorkig #city_of_newyork #ig_newyork#newyorkgram #nycgo #nybucketlist#nyclives #nypostnyc #streetsofnyc#winterinnewyork #downtownnyc#brooklynheights #newyork_photoshoots#newyork_originals #nyloveyou#nycityworld #newyorkbound#newyorkminute #imagesofnyc#travelnyc #nyc_exporers #nycbuildings#oneworldtradecenter #flatironbuilding#grandcentralterminal #newyorkknights #bigapplenyc #newyorknewyork#manhattanbridge #brooklynbridge
Here’s an example of one of my final products:
I used a generic caption that could go with any picture of NYC. I credited both the Instagram account it came from and the original source. If you look at the comments, you can see the original owner thanking me for sharing. And I added thirty hashtags to boost my post as well.
Posting
I now have a central repository of relevant media and a process of generating a caption for each of these posts. Now, it’s time to do just that — post.
I spun up an EC2 instance on AWS to host my code. I chose this route because it’s more reliable than my personal machine — it’s always on and connected to the internet and I knew it would all fit under the free-tier limits.
I wrote a Python script that randomly grabs one of these pictures and auto-generates a caption after the scraping and cleaning process is completed. Using the Instagram API, I was able to write code that does the actual posting for me. I scheduled a cron job to run around 8:00 AM, 2:00 PM, and 7:30 PM every day.
At this point, I’ve completely automated the content finding and posting process. I no longer have to worry about finding media and posting every day, it’s being done for me.
Growing My Following
It isn’t enough to just post — I need to enact some methodologies to grow my following as well. And since I won’t ever be on the account myself doing any of this manually, I’ll need to automate that too. The idea was to get my account exposed to an interested audience by interacting directly with those people.
The script that I wrote runs from 10:00 AM to 7:00 PM EST, the time range that I believed Instagram to be most active. Throughout the day, my account methodically follows, unfollows, and likes relevant users and photos in order to have the same be done back to me.
Following (More Data Science)
If you use Instagram, I’m sure you’ve been part of this before whether you realize it or not. This method is very common for accounts that are trying to increase their following. One day you follow an interesting Instagram page in the fitness niche, and the next day you’re being followed by a bunch of bodybuilders and fitness models. This seems extremely trivial, and it is, but it’s very effective.
The issue here is that you can’t just follow willy-nilly on Instagram. Their algorithm is very very strict, so they will cut you off or even ban your account if you go overboard and follow too many accounts in one day. Additionally, you can be following at most 7,500 users at one time on Instagram. After a lot of testing, I’ve found you can get away with following 400 people and unfollowing 400 people in a single day. Therefore, each follow is extremely precious. You don’t want to waste a follow on someone who is unlikely to follow you back because you only have so many users that you can follow in one day. I decided to capture the metadata of my activity and make a model to predict how likely someone would be to follow you back, so I wouldn’t waste a precious follow on someone who was unlikely to return the favor.
I spent a few minutes manually gathering 20+ bigger accounts in the same niche as me. I had no initial data, so the first few weeks would be me performing these actions to grow my following, but more importantly, I needed to capture as much metadata as possible so I can make my model.
I cycled through these 20+ related accounts and followed the users who followed them, liked their pictures, or commented on their posts. With each follow I captured as much metadata as possible about the user into a CSV file. Some of this metadata included their follower/following ratio, if they were public or private, or if they had a profile picture or not.
Every day, my script would go through this CSV and label the missing response variable, which is if they followed back or not. I gave each user two full days before labeling him or her 0, 1, or 2 — 2 being the most desirable outcome. 0 indicated that the user did not follow back, 1 indicated that they followed back but didn’t interact with me in my last ten pictures (liking or commenting), and 2 indicated if they followed back AND interacted on one of my last ten posts. My dataset looked something like this:
Response Variable:
Follow back (0,1,2)
Explanatory Variables:
Came from (The account in which this user was scraped from)
Method (whether they were a liker/commenter/follower of the above)
Timestamp
Private vs public
Missing profile picture
Is business profile
Following/follower ratio
Profile biography
Media count
Gender
Before running this data through a ML model, I did some exploratory data analysis and found that:
Likers and commenters were less likely to follow me back than followers, but they were more likely to engage with me. This tells me although they are less abundant in quantity, they are higher in quality.
Following people in the morning resulted in a higher follow-back rate than in the nighttime.
Public accounts are much more likely to follow me back than private accounts.
Females were more likely to follow back my NYC-based account than were males.
Those that were following more people than they had following them (following/follower ratio > 1.0) were more likely to follow me back.
From just the above insights, I was able to refine my initial search of users. I adjusted my settings to only follow in the morning and to look primarily for females. Now I was finally able to make a machine learning model to predict the likelihood of a follow back based on a user’s metadata before interacting with them. This allows me to not waste one of my already limited daily follows on someone who has a very small chance of following me back.
I chose to use the Random Forest algorithm to classify the follow back outcome. I originally was using a number of different decision trees before I had a set structure or outcome variable because I wanted to see the visual flowcharts that come along with them. The Random Forest is an enhancement of the decision tree that provides a number of tweaks to correct many of the inconsistencies in the individual trees. I was consistently seeing an accuracy of over 80% on my test data after modeling to my training data, so it was an effective model for me. I implemented this in my code on my scraped users to optimize follow usage and saw tremendous growth in my following.
Unfollowing
After two days, I would unfollow the people I had followed. This gave me enough time to capture if they would follow me back or not. This allowed me to collect data to continue to grow.
You have to unfollow the people you follow for two reasons. The first is that you cannot be following over 7,500 people at any time. The second is because — although artificial — you want to have your follower/following ratio as high as possible as it is a sign of a more desirable account.
This is an easy task because there aren’t any decisions that need to be made. You follow 400 people in a day, and two days later you unfollow those exact people.
Liking
Liking can also supplement your account. I didn’t put nearly as much effort in choosing the pictures to like as liking isn’t proven to give you that much of gain in followers compared to the following method described above. I simply gave a predefined set of hashtags, looped through their feeds, and liked the pictures in hopes those users would return the favor.
Auto-Sales
At this point, I have a complete self-sustaining robotic Instagram. My NYC page, on its own, is finding relevant content, weeding out bad potential posts, generating credits and a caption, and posting throughout the day. In addition, from 7:00 AM to 10:00 PM, it is growing its presence by automatically liking, following, and unfollowing with an intrigued audience which has been further redefined by some data science algorithms
For a month or two, I sat back and watched my product grow. I would see an increase of anywhere between 100 and 500 followers a day all the while enjoying some beautiful pictures of the city I love.
I was able to go about my life; work at my job, go out with friends, see a movie— never having to worry about spending any time manually growing my page. It had the formula to do its thing while I did my thing.
Once I had 20,000 followers I decided it was time to use this page to get some free meals. Again, I automated my sales pitch too.
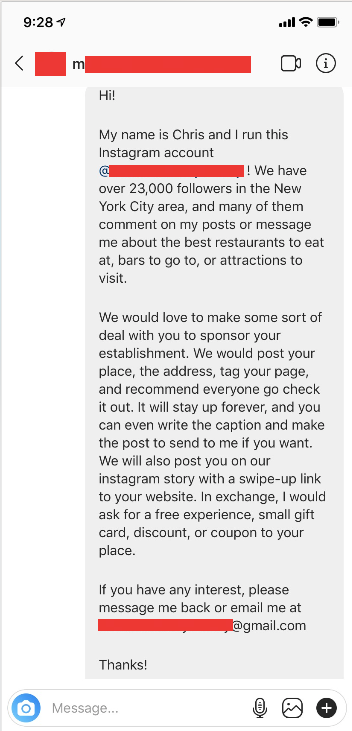
I made a direct message template which I tried to keep as generic as possible. I wanted to be able to use the same message whether it was a restaurant, a theatre, a museum, or a store. This is what I came up with:
Hello {ACCOUNT NAME}
My name is Chris and I run this Instagram account! We have over {FOLLOWER COUNT} followers in the New York City area, and many of them comment on my posts or message me about the best restaurants to eat at, bars to go to, or attractions to visit.
We would love to make some sort of deal with you to sponsor your establishment. We would post your place, the address, tag your page, and recommend everyone go check it out. It will stay up forever, and you can even write the caption and make the post to send to me if you want. We will also post you on our instagram story with a swipe-up link to your website. In exchange, I would ask for a free experience, small gift card, discount, or coupon to your place.
If you have any interest, please message me back or send me an email!
Thanks!
Chris
Here, I just need to impute the account name and the number of followers I have at the time of the message.
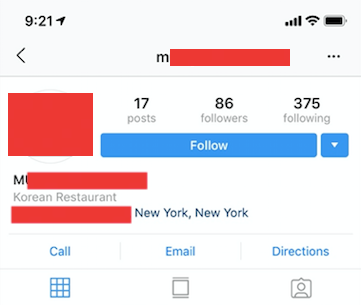
My goal was to find business Instagrams and give them my pitch. A business profile is slightly different from a normal one — it allows the user to add their email, phone number, directions, and other buttons on their page. But most importantly, they have a category label right on their profile.
The above is an example of a business profile. Right under the name in the top left, it says “Korean Restaurant” and it has call-to-action buttons such as call, email, and directions at the top.
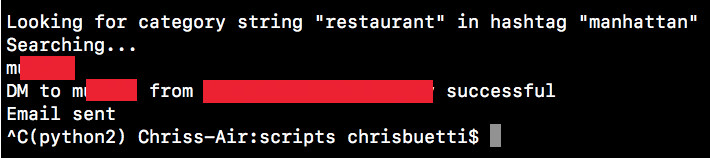
I wrote a Python script that looks for these pages and automatically sends them a message from my account. The script takes two parameters, a starting hashtag, and a string to look for in the category label. In my case, I used the hashtag “Manhattan” and the string “restaurant”.
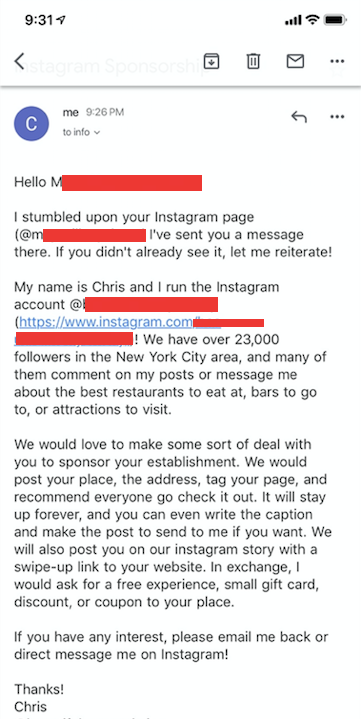
What this script does is it goes to the hashtag feed and loads a bunch of photos. It then loops through the posts until it hits one that has users tagged in the photo. If it does, it goes into the tags and checks if they are a business page. If it is, it looks at the category. If the category includes the word “restaurant”, it sends them my message. The nice part about business profiles is that they often have emails on their page. If they do, I automatically send them an email follow-up to my Instagram direct message. I can change the hashtag to something like #TimesSquare and I can change the string to something like “museum” if my goals change down the road.
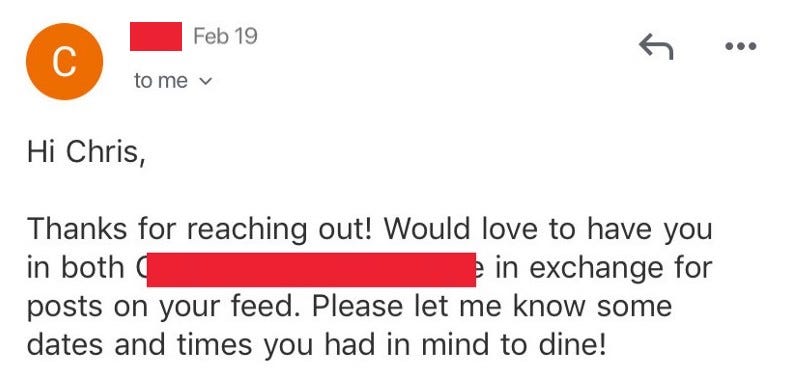
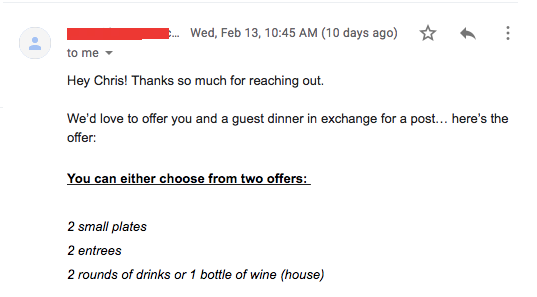
If I go into my account, I will see the message that it auto-generated and sent.
And if I go to my Gmail outbox, I’ll see:
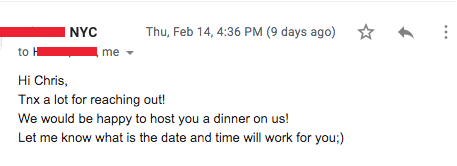
Finally, I have a script that monitors my inbox for any responses and alerts me if so. If there is a response, I finally do some manual work and negotiate with my potential client.
Along with the posting process and the growth process, this runs throughout the day without the need for any human manipulation.
The Results
The results are better than you might initially imagine. I have restaurants basically throwing gift cards and free meals my way in exchange for an Instagram promotion.
Due to the power of AI, automation, and data science — I am able to sit back and relax while my code does the work for me. It acts as a source of entertainment while at the same time being my salesman.
I hope this helps inspire some creativity when it comes to social media. Anyone can use these methods whether they are technical enough to automate or if they need to do it by hand. Instagram is a powerful tool and can be used for a variety of business benefits.









Comentários
Postar um comentário