Ferramentas de rastreamento BPF aprimoradas do Linux (eBPF)
Esta página mostra exemplos de ferramentas de análise de desempenho usando aprimoramentos para o BPF (Berkeley Packet Filter) que foram adicionados aos kernels da série Linux 4.x, permitindo que o BPF faça muito mais do que apenas pacotes de filtragem. Esses aprimoramentos permitem que os programas de análise personalizados sejam executados no rastreamento dinâmico do Linux, no rastreamento estático e nos eventos de criação de perfil.
O eBPF possui recursos de rastreamento sem fio semelhantes aos de DTrace e SystemTap, e já usei muitas das minhas ferramentas do DTraceToolkit para o eBPF. É adequado para responder perguntas como:
- Todas as operações ext4 demoram mais de 50 ms?
- O que é executar a latência da fila, como um histograma?
- Quais pacotes e aplicativos estão com retransmissões TCP? Trace de forma eficiente (sem rastrear envio / recebimento).
- Qual é o rastreamento da pilha quando os segmentos bloqueiam (fora da CPU) e quanto tempo eles bloqueiam?
EBPF também pode ser usado para módulos de segurança e redes definidas por software. Eu não estou cobrindo aqueles aqui (ainda assim, de qualquer maneira). Observe também: eBPF é chamado de apenas "BPF", especialmente em lkml.
Conteúdo da página:
Existem diferentes front-ends para eBPF, com bcc o mais popular. Nesta página, descreverei eBPF, bcc e demonstrei algumas das ferramentas de rastreamento que desenvolvi.
1. Captura de tela
Começando com uma captura de tela, aqui está um exemplo de rastreamento e exibição de E / S de bloco (disco) como um mapa de calor de latência:

Eu adicionei algumas anotações a essa captura de tela. Se você é novo nesta visualização, veja minha página em
mapas de calor de latência .
Isso usa o rastreamento dinâmico do kernel (kprobes) para as funções do instrumento para o problema e a conclusão das E / S do dispositivo de bloco. Os programas eBPF personalizados são executados quando estes kprobes são atingidos, que gravam carimbos de data / hora na questão de E / S, recuperam-nas na conclusão, calculam o tempo delta e, em seguida, armazenam isso em um histograma de log 2. O programa do espaço do usuário lê essa matriz de histograma periodicamente, uma vez por segundo, e desenha o mapa de calor. O resumo é feito no contexto do kernel, para eficiência.
2. One Liners
One-liners úteis usando as ferramentas
bcc (eBPF):
Ferramentas de uso único
# Trace novos processos:
Execsnoop
# O arquivo de rastreamento abre com o processo e o nome do arquivo:
Opensnoop
# Resumir latência de bloqueio de E / S (disco) como uma distribuição de poder de 2 por disco:
Biolatência -D
# Resumir o tamanho da E / S do bloco como uma distribuição de poder de 2 pelo nome do programa:
tamanho da mordida
# Trace operações comuns do sistema de arquivos ext4 com menos de 1 milissegundo:
Ext4slower 1
# Trace TCP conexões ativas (connect ()) com endereço IP e portas:
Tcpconnect
# Trace TCP passive connections (accept ()) com endereço IP e portas:
Tcpaccept
# Trace conexões TCP para a porta local 80, com duração da sessão:
Tcplife -L 80
# Trace TCP retransmissões com endereços IP e estado TCP:
Tcpretrans
# Testes de pilha de amostra a 49 Hertz por 10 segundos, emite formato dobrado (para gráficos de chama):
Perfil -fd -F 49 10
# Trace detalhes e latência das pesquisas de DNS do resolvedor:
Gethostlatency
# Comandos de rastreamento emitidos em todos os shells bash:
Linha de base
Multi Tools: Kernel Dynamic Tracing
# Contagem "tcp_send *" função do kernel, saída de impressão a cada segundo:
Funccount -i 1 'tcp_send *'
# Count "vfs_ *" chama PID 185:
Funccount -p 185 'vfs_ *'
# Nomes de arquivo de rastreio abertos, usando o rastreamento dinâmico da função do_sys_open do kernel ():
Trace 'p :: do_sys_open "% s", arg2'
# Igual a antes ("p :: é assumido se não for especificado):
Trace 'do_sys_open "% s", arg2'
# Trace o retorno do kernel do_sys_open () funciton e imprima o retval:
Trace 'r :: do_sys_open "ret:% d", retval'
# Trace do_nanosleep () função do kernel e o segundo argumento (modo), com os rastreios da pilha do kernel:
Traçar -K 'do_nanosleep "modo:% d", arg2'
# Trace o modo do_nanosleep () fornecendo o protótipo (não é necessário debuginfo):
Trace 'do_nanosleep (struct hrtimer_sleeper * t, modo enum hrtimer_mode) "mode:% d", mode'
# Trace do_nanosleep () com o endereço da tarefa (pode ser NULL), observando a desreferência:
Trace 'do_nanosleep (struct hrtimer_sleeper * t, enum hrtimer_mode mode) "tarefa:% x", t> tarefa "
# Contagem de frequência tcp_sendmsg () tamanho:
Argdist -C 'p :: tcp_sendmsg (struct sock * sk, struct msghdr * msg, size_t size): u32: tamanho'
# Resumir o tamanho do tcp_sendmsg () como um histograma de poder de 2:
Argdist -H 'p :: tcp_sendmsg (struct sock * sk, struct msghdr * msg, tamanho tamanho_t): u32: tamanho'
# Rastreios de pilha de contagem de frequência que levam à função submit_bio () (problema I / O do disco):
Stackcount submit_bio
# Resumir a latência (tempo gasto) pela função vfs_read () para PID 181:
Funclatency -p 181 -u vfs_read
Ferramentas múltiplas: rastreamento dinâmico de nível de usuário
# Trace a função de biblioteca libc nanosleep () e imprima os detalhes do sono solicitado:
Trace 'p: c: nanosleep (struct timespec * req) "% d sec% d nsec", req-> tv_sec, req-> tv_nsec'
# Contar a chamada libc write () para PID 181 por descritor de arquivo:
Argdist -p 181 -C 'p: c: write (int fd): int: fd'
# Resumir a latência (tempo gasto) por libc getaddrinfo (), como um histograma de power-of-2 em microssegundos:
Funclatency.py -u 'c: getaddrinfo'
Multi Tools: Kernel Static Tracing
# Conheça os rastreios de pilha que levaram a E / S do bloco emissor, rastreando seu ponto de sinalização do kernel:
Stackcount t: bloco: block_rq_insert
Em construção...
Ferramentas múltiplas: rastreamento estáticamente definido pelo usuário (USDT)
# Trace a sonda pthread_create USDT e imprima arg1 como hexadecimal:
Trace 'u: pthread: pthread_create "% x", arg1'
Em construção...
Estes one-liners demonstram vários recursos do bcc / eBPF. Você também pode imprimir isso como uma cheatsheet.
3. Apresentação
Uma conversa recente sobre ferramentas de rastreamento eBPF no LCA 2017 (
slideshare ,
youtube ):
Outras apresentações:
4. eBPF
O BPF se originou como uma tecnologia para otimizar filtros de pacotes. Se você executar o tcpdump com uma expressão (combinando em um host ou porta), ele é compilado em um bytecode BPF ótimo, que é executado por uma máquina virtual com sandboxs no kernel. O BPF avançado (também conhecido como eBPF, mas apenas o BPF) ampliou o que esta máquina virtual BPF poderia fazer: permitindo que ele funcionasse em eventos que não sejam pacotes e outras ações além de filtragem.
O eBPF pode ser usado para redes definidas por software, mitigação de DDoS (queda inicial de pacotes), melhorando o desempenho da rede (eXpress Data Path), detecção de intrusão e muito mais. Nesta página, estou focando seu uso em ferramentas de observabilidade, onde é usado como mostrado no seguinte fluxo de trabalho:

Nossa ferramenta de observabilidade possui o código BPF para executar determinadas ações: medir a latência, resumir como um histograma, pegar traços de pilha, etc. Esse código BPF é compilado para o código de byte BPF e depois enviado para o kernel, onde um verificador pode rejeitá-lo se for Considerado inseguro (que inclui não permitir loops ou ramos para trás). Se o bytecode BPF for aceito, ele poderá ser anexado a diferentes fontes de eventos:
- Kprobes : rastreamento dinâmico do kernel.
- Enrugamentos : rastreamento dinâmico do nível do usuário.
- Pontos de rastreamento : rastreamento estático do kernel.
- Perf_events : amostragem cronometrada e PMCs.
O programa BPF tem duas maneiras de passar dados medidos de volta para o espaço do usuário: por detalhes do evento ou por um mapa BPF. Os mapas BPF podem implementar arrays, matrizes associativas e histogramas, e são adequados para passar estatísticas de resumo.
4.1. Pré-requisitos
Um kernel do Linux compilado com CONFIG_BPF_SYSCALL (por exemplo, o Ubuntu faz isso) e pelo menos o kernel 4.4 (por exemplo, Ubuntu Xenial) para que o histograma, a estatística e o rastreamento por evento sejam suportados. O diagrama a seguir mostra outros recursos com a versão Linux eBPF suportada chegou em verde:

5. bcc
A Coleção BPF Compiler está em
github.com/iovisor/bcc e fornece uma grande coleção de ferramentas de exemplos de rastreamento, bem como interfaces Python e lua para desenvolvê-las. O diagrama no canto superior direito desta página ilustra estas ferramentas bcc.
Os pré-requisitos são iguais ao eBPF acima, e Python. Se você estiver em um kernel antigo (entre 4.1 e 4.8) e a ferramenta bcc que deseja executar não funciona, veja as ferramentas / diretório antigo do bcc, que podem ter uma versão legada que emprega soluções alternativas.
O código de rastreamento de exemplo pode ser encontrado no diretório bcc / examples / tracing e incluído no /docs/tutorial_bcc_python_developer.md. As ferramentas, sob / diretório de ferramentas, também podem servir como exemplos. Cada ferramenta também tem um exemplo de arquivo .txt em / tools e uma página de manual em / man / man8.
5.1. Instalação
Veja as
instruções de
instalação do
bcc para começar em distros diferentes do Linux. Aqui estão as instruções do Ubuntu recentes, como um exemplo:
# Echo "deb [trust = yes] https://repo.iovisor.org/apt/xenial xenial-nightly main" | \
Sudo tee /etc/apt/sources.list.d/iovisor.list
# sudo apt-get update
# sudo apt-get install bcc-tools
As ferramentas bcc serão instaladas em / usr / share / bcc / tools.
5.2. Lista de verificação de desempenho geral
Esta lista de verificação pode ser útil se você não sabe por onde começar. Ele roteia várias ferramentas bcc para analisar diferentes alvos, que podem desenterrar a atividade que você desconhecia anteriormente. Primeiro incluí isso no
tutorial bcc , depois de uma lista de verificação de ferramentas padrão do Linux. Supõe-se que você tenha executado esses conceitos básicos (dmesg, vmstat, iostat, top, etc.) e agora quer escavar mais fundo.
1. execsnoop
Trace novos processos via exec () syscalls e imprima o nome do processo pai e outros detalhes:
# Execsnoop
PCOMM PID RET ARGS
Bash 15887 0 / usr / bin / man ls
Préconv 15894 0 / usr / bin / preconv -e UTF-8
Homem 15896 0 / usr / bin / tbl
Homem 15897 0 / usr / bin / nroff -mandoc -rLL = 169n -rLT = 169n -Tutf8
Homem 15898 0 / usr / bin / pager -s
Nroff 15900 0 / usr / bin / locale charmap
Nroff 15901 0 / usr / bin / groff -mtty-char -Tutf8 -mandoc -rLL = 169n -rLT = 169n
Groff 15902 0 / usr / bin / troff -mtty-char -mandoc -rLL = 169n -rLT = 169n -Tutf8
Groff 15903 0 / usr / bin / grotty
[...]
2. opensnoop
Trace open () syscalls e nome do processo de impressão e detalhes do nome do caminho:
# Opensnoop
PID COMM FD ERR PATH
27159 catalina.sh 3 0 /apps/tomcat8/bin/setclasspath.sh
4057 redis-server 5 0 / proc / 4057 / stat
2360 redis-server 5 0 / proc / 2360 / stat
30668 sshd 4 0 / proc / sys / kernel / ngroups_max
30668 sshd 4 0 / etc / group
30668 sshd 4 0 /root/.ssh/authorized_keys
30668 sshd 4 0 /root/.ssh/authorized_keys
30668 sshd -1 2 / var / run / nologin
30668 sshd -1 2 / etc / nologin
30668 sshd 4 0 /etc/login.defs
30668 sshd 4 0 / etc / passwd
30668 sshd 4 0 / etc / shadow
30668 sshd 4 0 / etc / localtime
4510 snmp-pass 4 0 / proc / cpuinfo
[...]
3. ext4slower
Trace as operações lentas do ext4 que são mais lentas do que um limite fornecido (o bcc possui versões deste para btrfs, XFS e ZFS também):
# Ext4slower 1
Rastreando operações ext4 com menos de 1 ms
TIME COMM PID T BYTES OFF_KB LAT (ms) FILENAME
06:49:17 bash 3616 R 128 0 7,75 cksum
06:49:17 cksum 3616 R 39552 0 1.34 [
06:49:17 cksum 3616 R 96 0 5,36 2 a 3-2,7
06:49:17 cksum 3616 R 96 0 14,94 2to3-3.4
06:49:17 cksum 3616 R 10320 0 6.82 411toppm
06:49:17 cksum 3616 R 65536 0 4.01 a2p
06:49:17 cksum 3616 R 55400 0 8.77 ab
06:49:17 cksum 3616 R 36792 0 16.34 aclocal-1.14
06:49:17 cksum 3616 R 15008 0 19,31 acpi_listen
06:49:17 cksum 3616 R 6123 0 17.23 add-apt-repository
06:49:17 cksum 3616 R 6280 0 18.40 addpart
06:49:17 cksum 3616 R 27696 0 2.16 addr2line
06:49:17 cksum 3616 R 58080 0 10,11 ag
4. biolatência
Resumir a latência de E / S do dispositivo de bloco como um histograma a cada segundo:
# Biolatência -mT 1
Rastreamento do dispositivo do bloco I / O ... Pressione Ctrl-C para finalizar.
21:33:40
Msecs: distribuição de contagem
0 -> 1: 69 | ********************************************
2 -> 3: 16 | ********* |
4 -> 7: 6 | *** |
8 -> 15: 21 | ************ |
16 -> 31: 16 | ********* |
32 -> 63: 5 | ** |
64 -> 127: 1 | |
21:33:41
Msecs: distribuição de contagem
0 -> 1: 60 | ************************ |
2 -> 3: 100 | ***********************************************
4 -> 7: 41 | **************** |
8 -> 15: 11 | **** |
16 -> 31: 9 | *** |
32 -> 63: 6 | ** |
64 -> 127: 4 | * |
21:33:42
Msecs: distribuição de contagem
0 -> 1: 110 | *********************************************
2 -> 3: 78 | ********************************
4 -> 7: 64 | *********************** |
8 -> 15: 8 | ** |
16 -> 31: 12 | **** |
32 -> 63: 15 | ***** |
64 -> 127: 8 | ** |
[...]
5. biosnoop
E / S do dispositivo de bloco de rastreamento com detalhes de processo, disco e latência:
# Biosnoop
TEMPO (s) COMM PID DISK T SETOR BYTES LAT (ms)
0.000004001 supervisionar 1950 xvda1 W 13092560 4096 0.74
0.000178002 supervisionar 1950 xvda1 W 13092432 4096 0.61
0.001469001 supervisionar 1956 xvda1 W 13092440 4096 1.24
0.001588002 supervisionar 1956 xvda1 W 13115128 4096 1.09
1.022346001 supervisionar 1950 xvda1 W 13115272 4096 0.98
1.022568002 supervisionar 1950 xvda1 W 13188496 4096 0.93
1.023534000 supervisionar 1956 xvda1 W 13188520 4096 0.79
1.023585003 supervisionar 1956 xvda1 W 13189512 4096 0.60
2.003920000 xfsaild / md0 456 xvdc W 62901512 8192 0.23
2.003931001 xfsaild / md0 456 xvdb W 62901513 512 0.25
2.004034001 xfsaild / md0 456 xvdb W 62901520 8192 0.35
2.004042000 xfsaild / md0 456 xvdb W 63542016 4096 0.36
2.004204001 kworker / 0: 3 26040 xvdb W 41950344 65536 0.34
2.044352002 supervisionar 1950 xvda1 W 13192672 4096 0.65
[...]
6. cachestat
Mostra a proporção e o tamanho do hit / falta de cache da página e resuma todos os segundos:
# Cachestat
HITS MISSES DIRTIES READ_HIT% WRITE_HIT% BUFFERS_MB CACHED_MB
170610 41607 33 80,4% 19,6% 11 288
157693 6149 33 96,2% 3,7% 11 311
174483 20166 26 89,6% 10,4% 12 389
434778 35 40 100,0% 0,0% 12 389
435723 28 36 100,0% 0,0% 12 389
846183 83800 332534 55,2% 4,5% 13 553
96387 21 24 100,0% 0,0% 13 553
120258 29 44 99,9% 0,0% 13 553
255861 24 33 100,0% 0,0% 13 553
191388 22 32 100,0% 0,0% 13 553
[...]
7. tcpconnect
Trace TCP conexões ativas (connect ()):
# Tcpconnect
PID COMM IP SADDR DADDR DPORT
25333 recordProgra 4 127.0.0.1 127.0.0.1 28527
25338 curl 4 100.66.3.172 52.22.109.254 80
25340 curl 4 100.66.3.172 31.13.73.36 80
25342 curl 4 100.66.3.172 104.20.25.153 80
25344 curl 4 100.66.3.172 50.56.53.173 80
25365 recordProgra 4 127.0.0.1 127.0.0.1 28527
26119 ssh 6 :: 1 :: 1 22
25388 recordProgra 4 127.0.0.1 127.0.0.1 28527
25220 ssh 6 fe80: 8a3: 9dff: fed5: 6b19 fe80 :: 8a3: 9dff: fed5: 6b19 22
[...]
8. tcpaccept
Trace conexões passivas TCP (accept ()):
# Tcpaccept
PID COMM IP RADDR LADDR LPORT
2287 sshd 4 11.16.213.254 100.66.3.172 22
4057 redis-server 4 127.0.0.1 127.0.0.1 28527
4057 redis-server 4 127.0.0.1 127.0.0.1 28527
4057 redis-server 4 127.0.0.1 127.0.0.1 28527
4057 redis-server 4 127.0.0.1 127.0.0.1 28527
2287 sshd 6 :: 1 :: 1 22
4057 redis-server 4 127.0.0.1 127.0.0.1 28527
4057 redis-server 4 127.0.0.1 127.0.0.1 28527
2287 sshd 6 fe80 :: 8a3: 9dff: fed5: 6b19 fe80 :: 8a3: 9dff: fed5: 6b19 22
4057 redis-server 4 127.0.0.1 127.0.0.1 28527
[...]
9. tcpretrans
Transtornos TCP retransmissíveis e TLPs:
# Tcpretrans
TIME PID IP LADDR: LPORT T> RADDR: ESTADO DE RUA
01:55:05 0 4 10.153.223.157:22 R> 69.53.245.40:34619 ESTABELECIDO
01:55:05 0 4 10.153.223.157:22 R> 69.53.245.40:34619 ESTABELECIDO
01:55:17 0 4 10.153.223.157:22 R> 69.53.245.40:22957 ESTABELECIDO
[...]
10. gethostlatency
Mostrar latência para getaddrinfo / gethostbyname [2] chamadas de biblioteca, em todo o sistema:
# Gethostlatency
TIME PID COMM LATms HOST
06:10:24 28011 wget 90.00 www.iovisor.org
06:10:28 28127 wget 0.00 www.iovisor.org
06:10:41 28404 wget 9.00 www.netflix.com
06:10:48 28544 curl 35.00 www.netflix.com.au
06:11:10 29054 curl 31.00 www.plumgrid.com
06:11:16 29195 curl 3.00 www.facebook.com
06:11:24 25313 wget 3.00 www.usenix.org
06:11:25 29404 curl 72.00 foo
06:11:28 29475 curl 1.00 foo
[...]
11. runqlat
Mostrar a latência da fila de execução (agendador) como um histograma, a cada 5 segundos:
# Runqlat -m 5
Rastreamento da latência da fila de execução ... Pressione Ctrl-C para finalizar.
Msecs: distribuição de contagem
0 -> 1: 2085 | ********************************************
2 -> 3: 8 | |
4 -> 7: 20 | |
8 -> 15: 191 | *** |
16 -> 31: 420 | ******** |
Msecs: distribuição de contagem
0 -> 1: 1798 | **********************************************
2 -> 3: 11 | |
4 -> 7: 45 | * |
8 -> 15: 441 | ********* |
16 -> 31: 1030 | ********************** |
Msecs: distribuição de contagem
0 -> 1: 1588 | ************************************************
2 -> 3: 7 | |
4 -> 7: 49 | * |
8 -> 15: 556 | ************** |
16 -> 31: 1206 | *********************************
[...]
12. perfil
Rastros de pilha de amostra em 49 Hertz, então imprima pilhas exclusivas com o número de ocorrências vistas:
# Perfil
Amostragem em 49 Hertz de todos os tópicos pelo usuário + pilha de núcleo ... Pressione Ctrl-C para finalizar.
^ C
[...]
Ffffffff811a2eb0 find_get_entry
Ffffffff811a338d pagecache_get_page
Ffffffff811a51fa generic_file_read_iter
Ffffffff81231f30 __vfs_read
Ffffffff81233063 vfs_read
Ffffffff81234565 SyS_read
Ffffffff818739bb entry_SYSCALL_64_fastpath
00007f4757ff9680 read
- dd (14283)
29
Ffffffff8141c067 copy_page_to_iter
Ffffffff811a54e8 generic_file_read_iter
Ffffffff81231f30 __vfs_read
Ffffffff81233063 vfs_read
Ffffffff81234565 SyS_read
Ffffffff818739bb entry_SYSCALL_64_fastpath
00007f407617d680 lido
- dd (14288)
32
Ffffffff813af58c common_file_perm
Ffffffff813af6f8 apparmor_file_permission
Ffffffff8136f89b security_file_permission
Ffffffff81232f6e rw_verify_area
Ffffffff8123303e vfs_read
Ffffffff81234565 SyS_read
Ffffffff818739bb entry_SYSCALL_64_fastpath
00007f407617d680 lido
- dd (14288)
39
[...]
5.3. Ferramentas

A seção de ferramentas do
bcc no github os lista com descrições curtas. Essas ferramentas são principalmente para observabilidade e depuração de desempenho.
Existem dois tipos de ferramentas:
- Single purpose: These tools do one thing and do it well (Unix philosophy). They include execsnoop, opensnoop, ext4slower, biolatency, tcpconnect, oomkill, runqlat, etc. They should be easy to learn and use. Most of the previous examples in the General Performance Checklist were single purpose.
- Multi-tools: These are powerful tools that can do many things, provided you know which arguments and options to use. They featured in the one-liners section earlier on this page, and include trace, argdist, funccount, funclatency, and stackcount.
Each tool has three related files. Using biolatency as an example:
1/3. The tool
$ more tools/biolatency.py
#!/usr/bin/python
# @lint-avoid-python-3-compatibility-imports
#
# biolatency Summarize block device I/O latency as a histogram.
# For Linux, uses BCC, eBPF.
#
# USAGE: biolatency [-h] [-T] [-Q] [-m] [-D] [interval] [count]
#
# Copyright (c) 2015 Brendan Gregg.
# Licensed under the Apache License, Version 2.0 (the "License")
#
# 20-Sep-2015 Brendan Gregg Created this.
[...]
Tools begin with a block comment to describe basics: what the tool does, its synopsis, major change history.
2/3. An examples file
$ more tools/biolatency_example.txt
Demonstrations of biolatency, the Linux eBPF/bcc version.
biolatency traces block device I/O (disk I/O), and records the distribution
of I/O latency (time), printing this as a histogram when Ctrl-C is hit.
For example:
# ./biolatency
Tracing block device I/O... Hit Ctrl-C to end.
^C
usecs : count distribution
0 -> 1 : 0 | |
2 -> 3 : 0 | |
4 -> 7 : 0 | |
8 -> 15 : 0 | |
16 -> 31 : 0 | |
32 -> 63 : 0 | |
64 -> 127 : 1 | |
128 -> 255 : 12 |******** |
256 -> 511 : 15 |********** |
512 -> 1023 : 43 |******************************* |
1024 -> 2047 : 52 |**************************************|
2048 -> 4095 : 47 |********************************** |
4096 -> 8191 : 52 |**************************************|
8192 -> 16383 : 36 |************************** |
16384 -> 32767 : 15 |********** |
32768 -> 65535 : 2 |* |
65536 -> 131071 : 2 |* |
The latency of the disk I/O is measured from the issue to the device to its
completion. A -Q option can be used to include time queued in the kernel.
This example output shows a large mode of latency from about 128 microseconds
to about 32767 microseconds (33 milliseconds). The bulk of the I/O was
between 1 and 8 ms, which is the expected block device latency for
rotational storage devices.
The highest latency seen while tracing was between 65 and 131 milliseconds:
the last row printed, for which there were 2 I/O.
[...]
There are detailed examples files in the /tools directory, which include tool output and discussion of what it means.
3/3. A man page
$ nroff -man man/man8/biolatency.8 | more
biolatency(8) biolatency(8)
NAME
biolatency - Summarize block device I/O latency as a histogram.
SYNOPSIS
biolatency [-h] [-T] [-Q] [-m] [-D] [interval [count]]
DESCRIPTION
biolatency traces block device I/O (disk I/O), and records the distri-
bution of I/O latency (time). This is printed as a histogram either on
Ctrl-C, or after a given interval in seconds.
The latency of the disk I/O is measured from the issue to the device to
its completion. A -Q option can be used to include time queued in the
kernel.
This tool uses in-kernel eBPF maps for storing timestamps and the his-
togram, for efficiency.
This works by tracing various kernel blk_*() functions using dynamic
tracing, and will need updating to match any changes to these func-
tions.
Since this uses BPF, only the root user can use this tool.
REQUIREMENTS
CONFIG_BPF and bcc.
OPTIONS
-h Print usage message.
-T Include timestamps on output.
[...]
The man pages are the reference for what the tool does, what options it has, what the output means including column definitions, and any caveats including overhead.
5.4. Programming
Se você quiser escrever seus próprios programas bcc / eBPF, consulte o
Tutorial do desenvolvedor do PcB do
bcc . Tem mais de 15 lições que cobrem todas as funções e ressalvas que você provavelmente irá encontrar. Consulte também o
Guia de Referência do
bcc , que explica a API para eBPF C e o bcc Python. Eu criei ambos. Meu objetivo era ser prático e conciso: mostre exemplos reais e trechos de código, cubra internals e ressalvas, e faça o mais brevemente possível. Se você pressionar a página para baixo uma ou duas vezes, você atingirá o próximo título, já que deliberadamente mantive as seções baixas e evite uma parede de texto.
Para as pessoas que têm mais um interesse casual em como o bcc / BPF está programado, resumirei as coisas-chave para saber a seguir, e depois explico o código de uma ferramenta em detalhes.
5 coisas a saber
Se quiser mergulhar na codificação sem ler essas referências, aqui estão cinco coisas a serem conhecidas:
- O eBPF C está restrito : sem loops ou chamadas de função do kernel. Você só pode usar as funções bpf_ * (e alguns compilados com compilação).
- Toda a memória deve ser lida na pilha BPF primeiro antes da manipulação através do bpf_probe_read (), que faz as verificações necessárias. Se você deseja desreferenciar a-> b-> c-> d, então tente fazer isso primeiro, pois o bcc possui um reescritor que pode transformá-lo no bpf_probe_read () s necessário. Se não funcionar, adicione bpf_probe_reads () s.
- Existem 3 maneiras de produzir dados do kernel para o usuário:
- Bpf_trace_printk () . Depuração apenas, isso escreve para trace_pipe e pode colidir com outros programas e traçadores. É muito simples, então eu usei isso no início do tutorial, mas você deve usar o seguinte em vez disso:
- BPF_PERF_OUTPUT () . Uma maneira de enviar detalhes por evento para o espaço do usuário, através de uma estrutura personalizada que você define. (O programa Python atualmente precisa de uma versão ct da definição da estrutura - isso deve ser automático um dia.)
- BPF_HISTOGRAM () ou outros mapas BPF. Os mapas são um hash de valores-chave a partir do qual estruturas de dados mais avançadas podem ser criadas. Eles podem ser usados para estatísticas de resumo ou histogramas, e ler periodicamente do espaço do usuário (eficiente).
- Use pontos de rastreamento estáticos (traceponits / USDT) em vez de rastreamento dinâmico (kprobes / upsrobes) sempre que possível. Muitas vezes não é possível, mas tente. O rastreamento dinâmico é uma API instável, então seus programas serão quebrados se o código que está instrumentando mudar de uma versão para outra.
- Verifique os desenvolvimentos do bcc e os novos idiomas . Comparado com outros traçadores (DTrace / SystemTap), o bcc Python é muito mais detalhado e laborioso para codificar. Vai melhorar, então, se é um incômodo hoje, tenha em mente que ele irá melhorar. Também há esforços para criar um idioma de nível superior, que provavelmente usará o bcc (seja adicionado ao bcc como outro front-end, ou seja dependente das bibliotecas do bcc).
Exemplo de ferramenta: biolatency.py
1 #! / Usr / bin / python
2 # @ lint-avoid-python-3-compatibilidade-importações
Linha 1: somos Python. Linha 2: Eu acredito que suprime um aviso de fiapos (estes foram adicionados ao ambiente de construção de outras empresas principais).
3 #
4 # biolatência Resuma a latência de I / O do dispositivo de bloco como um histograma.
5 # Para Linux, usa BCC, eBPF.
6 #
7 # USO: biolatência [-h] [-T] [-Q] [-m] [-D] [intervalo] [contar]
8 #
9 # Direitos autorais (c) 2015 Brendan Gregg.
10 # Licenciado sob a Licença Apache, Versão 2.0 (a "Licença")
11 #
12 # 20-Set-2015 Brendan Gregg Criou isso.
Tenho um certo estilo para os meus comentários de cabeçalho. A Linha 4 nomeia a ferramenta e descreve uma única frase. A linha 5 adiciona quaisquer ressalvas: apenas para Linux, usa BCC / eBPF. Em seguida, possui uma linha de sinopse, direitos autorais e um histórico de mudanças importantes.
13
14 de __future__ import print_function
15 do BPC de importação do bcc
16 do tempo importar sono, strftime
17 importação argparse
Observe que importamos o BPF, o que usaremos para interagir com eBPF no kernel.
18
19 argumentos
20 exemplos = "" "exemplos:
21 ./biolatency # resume a latência de bloqueio I / O como um histograma
22 ./biolatência 1 10 # imprimir 1 segundo resumos, 10 vezes
23 ./biolatency -mT 1 # 1s resumos, milissegundos e timestamps
24 ./biolatency -Q # inclui o tempo de espera do SO no tempo de E / S
25 ./biolatência -D # mostra cada dispositivo de disco separadamente
26 "" "
27 parser = argparse.ArgumentParser (
28 descrição = "Resumir a latência de I / O do dispositivo de bloco como um histograma",
29 formatter_class = argparse.RawDescriptionHelpFormatter,
30 epilog = exemplos)
31 parser.add_argument ("- T", "--timestamp", action = "store_true",
32 help = "incluir timestamp na saída")
33 parser.add_argument ("- Q", "--queued", action = "store_true",
34 help = "incluir tempo de espera do sistema operacional no tempo de E / S")
35 parser.add_argument ("- m", "--milliseconds", action = "store_true",
36 help = "histograma de milissegundo")
37 parser.add_argument ("- D", "--disks", action = "store_true",
38 help = "imprimir um histograma por dispositivo de disco")
39 parser.add_argument ("interval", nargs = "?", Default = 99999999,
40 help = "intervalo de saída, em segundos")
41 parser.add_argument ("count", nargs = "?", Default = 99999999,
42 help = "número de saídas")
43 args = parser.parse_args ()
44 countdown = int (args.count)
45 debug = 0
46
As linhas 19 a 44 são processamento de argumentos. Estou usando Argparse de Python aqui.
Minha intenção é fazer deste uma ferramenta similar a Unix, algo semelhante ao vmstat / iostat, para facilitar a reconhecer e aprender. Daí o estilo de opções e argumentos, e também fazer uma coisa e fazê-lo bem. Nesse caso, mostrando a latência de E / S do disco como um histograma. Eu poderia ter adicionado um modo para despejar detalhes por evento, mas fez isso uma ferramenta separada, biosnoop.py.
Você pode estar escrevendo bcc / eBPF por outros motivos, incluindo agentes para outro software de monitoramento, e não precisa se preocupar com a interface do usuário.
47 # define o programa BPF
48 bpf_text = "" "
49 #include <uapi / linux / ptrace.h >>
50 #include <linux / blkdev.h>
51
52 typedef struct disk_key {
Disco de 53 caracteres [DISK_NAME_LEN];
Ranhura 54 u64;
55} disk_key_t;
56 BPF_HASH (início, pedido de estrutura *);
57 ARMAZENAMENTO
58
59 // bloqueio de tempo I / O
60 int trace_req_start (struct pt_regs * ctx, struct request * req)
61 {
62 u64 ts = bpf_ktime_get_ns ();
63 start.update (& req, & ts);
64 retornam 0;
65}
66
67 // saída
68 int trace_req_completion (struct pt_regs * ctx, struct request * req)
69 {
70 u64 * colher de chá, delta;
71
72 // buscar timestamp e calcular o delta
73 tsp = start.lookup (& req);
74 se (tsp == 0) {
75 retornar 0; // problema perdido
76}
77 delta = bpf_ktime_get_ns () - * tsp;
78 FATOR
79
80 // armazenar como histograma
81 LOJA
82
83 start.delete (& req);
84 retorna 0;
85}
86 "" "
O programa EBPF é declarado como um C em linha atribuído à variável bpf_text.
A linha 56 declara uma matriz de hash "início", que usa um ponteiro de solicitação de estrutura como a chave. A função trace_req_start () obtém um carimbo de data / hora usando bpf_ktime_get_ns () e, em seguida, armazena-o neste hash, digitado por * req (eu apenas estou usando esse endereço de ponteiro como UUID). A função trace_req_completion () então faz uma pesquisa no hash com o * req, para buscar a hora de início da solicitação, que é então usada para calcular o tempo delta na linha 77. A linha 83 exclui o timestamp do hash.
Os protótipos para essas funções começam com uma estrutura pt_regs * para registros e, em seguida, como muitos dos argumentos da função sondada que você deseja incluir. Eu incluí o argumento da primeira função em cada pedido de estrutura *.
Este programa também declara o armazenamento para os dados de saída e o armazena, mas há um problema: a biolatência possui uma opção -D para emitir histogramas por disco, em vez de um histograma para tudo, e isso altera o código de armazenamento. Então, este programa eBPF contém o texto STORAGE e STORE (e FACTOR), que são apenas strings que vamos pesquisar e substituir com o próximo código, dependendo das opções. Prefiro evitar código-que-escreve-código, se possível, uma vez que dificulta a depuração.
87
88 # substituições de código
89 se args.milliseconds:
90 bpf_text = bpf_text.replace ('FATOR', 'delta / = 1000000;')
91 label = "msecs"
Mais 92:
93 bpf_text = bpf_text.replace ('FACTOR', 'delta / = 1000;')
94 label = "usecs"
95 se args.disks:
96 bpf_text = bpf_text.replace ('ARMAZENAMENTO',
97 'BPF_HISTOGRAM (dist, disk_key_t);')
98 bpf_text = bpf_text.replace ('STORE',
99 'chave disk_key_t = {.slot = bpf_log2l (delta)}; '+
100 'bpf_probe_read (& key.disk, sizeof (key.disk),' +
101 'req-> rq_disk-> disk_name); Dist.incremento (chave); ')
Mais 102:
103 bpf_text = bpf_text.replace ('ARMAZENAMENTO', 'BPF_HISTOGRAMA (dist);')
104 bpf_text = bpf_text.replace ('STORE',
105 'dist.increment (bpf_log2l (delta));')
O código FACTOR apenas muda as unidades do tempo que estamos gravando, dependendo da opção -m.
A linha 95 verifica se o pedido por disco foi solicitado (-D) e, em caso afirmativo, substitui as cordas STORAGE e STORE com o código para fazer histogramas por disco. Ele usa a estrutura disk_key declarada na linha 52, que é o nome do disco e o slot (balde) no histograma power-of-2. A linha 99 leva o tempo delta e converte-o no índice de slot power-of-2 usando a função helper bpf_log2l (). As linhas 100 e 101 obtêm o nome do disco através de bpf_probe_read (), que é como todos os dados são copiados na pilha da BPF para operação. A Linha 101 inclui muitas dereferências: req-> rq_disk, rq_disk-> disk_name: o reescritor do bcc também transformou estas em bpf_probe_read () s.
As linhas 103 a 105 lidam com o caso do histograma único (não por disco). Um histograma é declarado chamado "dist" usando a macro BPF_HISTOGRAM. O slot (balde) é encontrado usando a função helper bpf_log2l () e, em seguida, incrementado no histograma.
Este exemplo é um pouco corajoso, o que é bom (realista) e ruim (intimidante). Veja o tutorial que liguei anteriormente para exemplos mais simples.
106 se debug:
107 imprimir (bpf_text)
Como eu tenho código que escreve código, preciso de uma maneira de depurar o resultado final. Se o debug estiver configurado, imprima.
108
109 # load BPF program
110 b = BPF (texto = bpf_text)
111 se args.queued:
112 b.attach_kprobe (evento = "blk_account_io_start", fn_name = "trace_req_start")
Mais 113:
114 b.attach_kprobe (evento = "blk_start_request", fn_name = "trace_req_start")
115 b.attach_kprobe (evento = "blk_mq_start_request", fn_name = "trace_req_start")
116 b.attach_kprobe (evento = "blk_account_io_completion",
117 fn_name = "trace_req_completion")
118
A linha 110 carrega o programa eBPF.
Uma vez que este programa foi escrito antes do EBPF possuir suporte para tracepoint, escrevi para usar kprobes (rastreamento dinâmico do kernel). Ele deve ser reescrito para usar pontos de rastreamento, pois eles são uma API estável, embora isso também requer uma versão do kernel posterior (Linux 4.7+).
Biolatency.py tem uma opção -Q para o tempo incluído na fila no kernel. Podemos ver como é implementado neste código. Se estiver configurado, a linha 112 atribui a nossa função eBPF trace_req_start () com um kprobe na função de kernel blk_account_io_start (), que rastreia a solicitação quando está na fila no kernel. Se não for definido, lnes 114 e 115 anexam nossa função eBPF a diferentes funções do kernel, que é quando o disco I / O é emitido (pode ser um desses). Isso só funciona porque o primeiro argumento para qualquer uma dessas funções de kernels é o mesmo: solicitação de estrutura *. Se seus argumentos fossem diferentes, eu precisaria de funções eBPF separadas para cada um para lidar com isso.
119 imprimir ("Detecção de bloqueio do dispositivo I / O ... Pressione Ctrl-C para finalizar.")
120
121 # saída
122 saindo = 0 se args.interval else 1
123 dist = b.get_table ("dist")
A linha 123 busca o histograma "dist" que foi declarado e preenchido pelo código STORAGE / STORE.
124 enquanto (1):
125:
126 sleep (int (args.interval))
127, exceto KeyboardInterrupt:
128 saindo = 1
129
130 imprimir ()
131 if args.timestamp:
132 imprimir ("% - 8s \ n"% strftime ("% H:% M:% S"), final = "")
133
134 dist.print_log2_hist (rótulo, "disco")
135 dist.clear ()
136
Contagem regressiva 137 - = 1
138 se sair ou contagem regressiva == 0:
139 exit ()
Isso tem lógica para imprimir todos os intervalos, um certo número de vezes (contagem regressiva). Linhas 131 e 132 imprime um carimbo de data / hora se a opção -T foi usada.
A linha 134 imprime o histograma ou histogramas se estiver fazendo por disco. O primeiro argumento é a variável de rótulo, que contém "usecs" ou "msecs", e decora a coluna de valores na saída. O segundo argumento é rótulos da chave secundária, se dist tiver histogramas por disco. Como print_log2_hist () pode identificar se este é um histograma único ou tem uma chave secundária, vou deixar um exercício aventureiro no spelunking de código dos componentes internos do eBPF e bcc.
A linha 135 limpa o histograma, pronto para o próximo intervalo.
Aqui está uma amostra de saída:
# Biolatência
Rastreamento do dispositivo do bloco I / O ... Pressione Ctrl-C para finalizar.
^ C
Usecs: distribuição de contagem
0 -> 1: 0 | |
2 -> 3: 0 | |
4 -> 7: 0 | |
8 -> 15: 0 | |
16 -> 31: 0 | |
32 -> 63: 0 | |
64 -> 127: 1 | |
128 -> 255: 12 | ******** |
256 -> 511: 15 | ********** |
512 -> 1023: 43 | ******************************* |
1024 -> 2047: 52 | ***************************************
2048 -> 4095: 47 | *************************************
4096 -> 8191: 52 | ****************************************
8192 -> 16383: 36 | *******************************
16384 -> 32767: 15 | ********** |
32768 -> 65535: 2 | * |
65536 -> 131071: 2 | * |
Saída por disco:
# Biolatência -D
Rastreamento do dispositivo do bloco I / O ... Pressione Ctrl-C para finalizar.
^ C
Disk = 'xvdb'
Usecs: distribuição de contagem
0 -> 1: 0 | |
2 -> 3: 0 | |
4 -> 7: 0 | |
8 -> 15: 0 | |
16 -> 31: 0 | |
32 -> 63: 0 | |
64 -> 127: 18 | **** |
128 -> 255: 167 | **********************************************
256 -> 511: 90 | ********************* |
Disk = 'xvdc'
Usecs: distribuição de contagem
0 -> 1: 0 | |
2 -> 3: 0 | |
4 -> 7: 0 | |
8 -> 15: 0 | |
16 -> 31: 0 | |
32 -> 63: 0 | |
64 -> 127: 22 | **** |
128 -> 255: 179 | **************************************************************************
256 -> 511: 88 | ******************* |
Disco = 'xvda1'
Usecs: distribuição de contagem
0 -> 1: 0 | |
2 -> 3: 0 | |
4 -> 7: 0 | |
8 -> 15: 0 | |
16 -> 31: 0 | |
32 -> 63: 0 | |
64 -> 127: 0 | |
128 -> 255: 0 | |
256 -> 511: 167 | **********************************************
512 -> 1023: 44 | ********** |
1024 -> 2047: 9 | ** |
2048 -> 4095: 4 | |
4096 -> 8191: 34 | ******** |
8192 -> 16383: 44 | ********** |
16384 -> 32767: 33 | ******* |
32768 -> 65535: 1 | |
65536 -> 131071: 1 | |
A partir da saída, podemos ver que xvdb e xvdc possuem histogramas de latência semelhantes, enquanto que xvda1 é bastante diferente e bimodal, com um modo de latência maior entre 4 e 32 milissegundos.
6. perf
EBPF também pode ser usado a partir do comando perf de Linux (aka perf_events) no Linux 4.4 e mais recente. Quanto mais novo for o melhor, como o suporte perf / BPF continua melhorando com cada versão. Eu já forneci um exemplo até agora na minha página
perf :
perf eBPF .
7. Referências
8. Agradecimentos
Muitas pessoas trabalharam em traçadores e contribuíram de maneiras diferentes ao longo dos anos para chegar onde estamos hoje, incluindo aqueles que trabalharam nas estruturas Linux que o bcc / eBPF usa: pontos de rastreamento, kprobes, arranha-céus, ftrace e perf_events. Os contribuidores mais recentes incluem Alexei Starovoitov, que liderou o desenvolvimento do eBPF, e Brenden Blanco, que liderou o desenvolvimento do bcc. Muitas das ferramentas de bcc de propósito único foram escritas por mim (execsnoop, opensnoop, biolatency, ext4slower, tcpconnect, gethostlatency, etc.) e duas das mais importantes ferramentas múltiplas (trace e argdist) foram escritas por Sasha Goldshtein. Eu escrevi uma lista mais longa de agradecimentos no final
desta publicação . Obrigado a todos!
9. Atualizações
Este é principalmente o meu próprio trabalho, apenas porque eu tenho meus próprios URLs à disposição para listar. Eu consertarei isso e continuarei adicionando postagens externas.
2015
2016
- Linux eBPF Stack Trace Hack (bcc)
- Gráfico de Fluxo Off-CPU eBPF do Linux (bcc)
- Linux Wakeup e Off-Wake Profiling (bcc)
- Protótipo do gráfico de cadeia Linux (bcc)
- Rolamentos eBPF / bcc do Linux
- Linux BPF / bcc Road Ahead
- Ubuntu Xenial bcc / BPF
- Recursos de segurança de rastreamento do Linux CCC / BPF
- Linux MySQL Query Query Tracing com bcc / BPF
- Rastreamento de latência Linux bcc / BPF ext4
Ferramentas de rastreamento BPF aprimoradas do Linux (eBPF)
Esta página mostra exemplos de ferramentas de análise de desempenho usando aprimoramentos para o BPF (Berkeley Packet Filter) que foram adicionados aos kernels da série Linux 4.x, permitindo que o BPF faça muito mais do que apenas pacotes de filtragem. Esses aprimoramentos permitem que os programas de análise personalizados sejam executados no rastreamento dinâmico do Linux, no rastreamento estático e nos eventos de criação de perfil.
O eBPF possui recursos de rastreamento sem fio semelhantes aos de DTrace e SystemTap, e já usei muitas das minhas ferramentas do DTraceToolkit para o eBPF. É adequado para responder perguntas como:
- Todas as operações ext4 demoram mais de 50 ms?
- O que é executar a latência da fila, como um histograma?
- Quais pacotes e aplicativos estão com retransmissões TCP? Trace de forma eficiente (sem rastrear envio / recebimento).
- Qual é o rastreamento da pilha quando os segmentos bloqueiam (fora da CPU) e quanto tempo eles bloqueiam?
EBPF também pode ser usado para módulos de segurança e redes definidas por software. Eu não estou cobrindo aqueles aqui (ainda assim, de qualquer maneira). Observe também: eBPF é chamado de apenas "BPF", especialmente em lkml.
Conteúdo da página:
Existem diferentes front-ends para eBPF, com bcc o mais popular. Nesta página, descreverei eBPF, bcc e demonstrei algumas das ferramentas de rastreamento que desenvolvi.
1. Captura de tela
Começando com uma captura de tela, aqui está um exemplo de rastreamento e exibição de E / S de bloco (disco) como um mapa de calor de latência:
Eu adicionei algumas anotações a essa captura de tela. Se você é novo nesta visualização, veja minha página em
mapas de calor de latência .
Isso usa o rastreamento dinâmico do kernel (kprobes) para as funções do instrumento para o problema e a conclusão das E / S do dispositivo de bloco. Os programas eBPF personalizados são executados quando estes kprobes são atingidos, que gravam carimbos de data / hora na questão de E / S, recuperam-nas na conclusão, calculam o tempo delta e, em seguida, armazenam isso em um histograma de log 2. O programa do espaço do usuário lê essa matriz de histograma periodicamente, uma vez por segundo, e desenha o mapa de calor. O resumo é feito no contexto do kernel, para eficiência.
2. One Liners
One-liners úteis usando as ferramentas
bcc (eBPF):
Ferramentas de uso único
# Trace novos processos:
Execsnoop
# O arquivo de rastreamento abre com o processo e o nome do arquivo:
Opensnoop
# Resumir latência de bloqueio de E / S (disco) como uma distribuição de poder de 2 por disco:
Biolatência -D
# Resumir o tamanho da E / S do bloco como uma distribuição de poder de 2 pelo nome do programa:
tamanho da mordida
# Trace operações comuns do sistema de arquivos ext4 com menos de 1 milissegundo:
Ext4slower 1
# Trace TCP conexões ativas (connect ()) com endereço IP e portas:
Tcpconnect
# Trace TCP passive connections (accept ()) com endereço IP e portas:
Tcpaccept
# Trace conexões TCP para a porta local 80, com duração da sessão:
Tcplife -L 80
# Trace TCP retransmissões com endereços IP e estado TCP:
Tcpretrans
# Testes de pilha de amostra a 49 Hertz por 10 segundos, emite formato dobrado (para gráficos de chama):
Perfil -fd -F 49 10
# Trace detalhes e latência das pesquisas de DNS do resolvedor:
Gethostlatency
# Comandos de rastreamento emitidos em todos os shells bash:
Linha de base
Multi Tools: Kernel Dynamic Tracing
# Contagem "tcp_send *" função do kernel, saída de impressão a cada segundo:
Funccount -i 1 'tcp_send *'
# Count "vfs_ *" chama PID 185:
Funccount -p 185 'vfs_ *'
# Nomes de arquivo de rastreio abertos, usando o rastreamento dinâmico da função do_sys_open do kernel ():
Trace 'p :: do_sys_open "% s", arg2'
# Igual a antes ("p :: é assumido se não for especificado):
Trace 'do_sys_open "% s", arg2'
# Trace o retorno do kernel do_sys_open () funciton e imprima o retval:
Trace 'r :: do_sys_open "ret:% d", retval'
# Trace do_nanosleep () função do kernel e o segundo argumento (modo), com os rastreios da pilha do kernel:
Traçar -K 'do_nanosleep "modo:% d", arg2'
# Trace o modo do_nanosleep () fornecendo o protótipo (não é necessário debuginfo):
Trace 'do_nanosleep (struct hrtimer_sleeper * t, modo enum hrtimer_mode) "mode:% d", mode'
# Trace do_nanosleep () com o endereço da tarefa (pode ser NULL), observando a desreferência:
Trace 'do_nanosleep (struct hrtimer_sleeper * t, enum hrtimer_mode mode) "tarefa:% x", t> tarefa "
# Contagem de frequência tcp_sendmsg () tamanho:
Argdist -C 'p :: tcp_sendmsg (struct sock * sk, struct msghdr * msg, size_t size): u32: tamanho'
# Resumir o tamanho do tcp_sendmsg () como um histograma de poder de 2:
Argdist -H 'p :: tcp_sendmsg (struct sock * sk, struct msghdr * msg, tamanho tamanho_t): u32: tamanho'
# Rastreios de pilha de contagem de frequência que levam à função submit_bio () (problema I / O do disco):
Stackcount submit_bio
# Resumir a latência (tempo gasto) pela função vfs_read () para PID 181:
Funclatency -p 181 -u vfs_read
Ferramentas múltiplas: rastreamento dinâmico de nível de usuário
# Trace a função de biblioteca libc nanosleep () e imprima os detalhes do sono solicitado:
Trace 'p: c: nanosleep (struct timespec * req) "% d sec% d nsec", req-> tv_sec, req-> tv_nsec'
# Contar a chamada libc write () para PID 181 por descritor de arquivo:
Argdist -p 181 -C 'p: c: write (int fd): int: fd'
# Resumir a latência (tempo gasto) por libc getaddrinfo (), como um histograma de power-of-2 em microssegundos:
Funclatency.py -u 'c: getaddrinfo'
Multi Tools: Kernel Static Tracing
# Conheça os rastreios de pilha que levaram a E / S do bloco emissor, rastreando seu ponto de sinalização do kernel:
Stackcount t: bloco: block_rq_insert
Em construção...
Ferramentas múltiplas: rastreamento estáticamente definido pelo usuário (USDT)
# Trace a sonda pthread_create USDT e imprima arg1 como hexadecimal:
Trace 'u: pthread: pthread_create "% x", arg1'
Em construção...
Estes one-liners demonstram vários recursos do bcc / eBPF. Você também pode imprimir isso como uma cheatsheet.
3. Apresentação
Uma conversa recente sobre ferramentas de rastreamento eBPF no LCA 2017 (
slideshare ,
youtube ):
Outras apresentações:
4. eBPF
O BPF se originou como uma tecnologia para otimizar filtros de pacotes. Se você executar o tcpdump com uma expressão (combinando em um host ou porta), ele é compilado em um bytecode BPF ótimo, que é executado por uma máquina virtual com sandboxs no kernel. O BPF avançado (também conhecido como eBPF, mas apenas o BPF) ampliou o que esta máquina virtual BPF poderia fazer: permitindo que ele funcionasse em eventos que não sejam pacotes e outras ações além de filtragem.
O eBPF pode ser usado para redes definidas por software, mitigação de DDoS (queda inicial de pacotes), melhorando o desempenho da rede (eXpress Data Path), detecção de intrusão e muito mais. Nesta página, estou focando seu uso em ferramentas de observabilidade, onde é usado como mostrado no seguinte fluxo de trabalho:
Nossa ferramenta de observabilidade possui o código BPF para executar determinadas ações: medir a latência, resumir como um histograma, pegar traços de pilha, etc. Esse código BPF é compilado para o código de byte BPF e depois enviado para o kernel, onde um verificador pode rejeitá-lo se for Considerado inseguro (que inclui não permitir loops ou ramos para trás). Se o bytecode BPF for aceito, ele poderá ser anexado a diferentes fontes de eventos:
- Kprobes : rastreamento dinâmico do kernel.
- Enrugamentos : rastreamento dinâmico do nível do usuário.
- Pontos de rastreamento : rastreamento estático do kernel.
- Perf_events : amostragem cronometrada e PMCs.
O programa BPF tem duas maneiras de passar dados medidos de volta para o espaço do usuário: por detalhes do evento ou por um mapa BPF. Os mapas BPF podem implementar arrays, matrizes associativas e histogramas, e são adequados para passar estatísticas de resumo.
4.1. Pré-requisitos
Um kernel do Linux compilado com CONFIG_BPF_SYSCALL (por exemplo, o Ubuntu faz isso) e pelo menos o kernel 4.4 (por exemplo, Ubuntu Xenial) para que o histograma, a estatística e o rastreamento por evento sejam suportados. O diagrama a seguir mostra outros recursos com a versão Linux eBPF suportada chegou em verde:
5. bcc
A Coleção BPF Compiler está em
github.com/iovisor/bcc e fornece uma grande coleção de ferramentas de exemplos de rastreamento, bem como interfaces Python e lua para desenvolvê-las. O diagrama no canto superior direito desta página ilustra estas ferramentas bcc.
Os pré-requisitos são iguais ao eBPF acima, e Python. Se você estiver em um kernel antigo (entre 4.1 e 4.8) e a ferramenta bcc que deseja executar não funciona, veja as ferramentas / diretório antigo do bcc, que podem ter uma versão legada que emprega soluções alternativas.
O código de rastreamento de exemplo pode ser encontrado no diretório bcc / examples / tracing e incluído no /docs/tutorial_bcc_python_developer.md. As ferramentas, sob / diretório de ferramentas, também podem servir como exemplos. Cada ferramenta também tem um exemplo de arquivo .txt em / tools e uma página de manual em / man / man8.
5.1. Instalação
Veja as
instruções de
instalação do
bcc para começar em distros diferentes do Linux. Aqui estão as instruções do Ubuntu recentes, como um exemplo:
# Echo "deb [trust = yes] https://repo.iovisor.org/apt/xenial xenial-nightly main" | \
Sudo tee /etc/apt/sources.list.d/iovisor.list
# sudo apt-get update
# sudo apt-get install bcc-tools
As ferramentas bcc serão instaladas em / usr / share / bcc / tools.
5.2. Lista de verificação de desempenho geral
Esta lista de verificação pode ser útil se você não sabe por onde começar. Ele roteia várias ferramentas bcc para analisar diferentes alvos, que podem desenterrar a atividade que você desconhecia anteriormente. Primeiro incluí isso no
tutorial bcc , depois de uma lista de verificação de ferramentas padrão do Linux. Supõe-se que você tenha executado esses conceitos básicos (dmesg, vmstat, iostat, top, etc.) e agora quer escavar mais fundo.
1. execsnoop
Trace novos processos via exec () syscalls e imprima o nome do processo pai e outros detalhes:
# Execsnoop
PCOMM PID RET ARGS
Bash 15887 0 / usr / bin / man ls
Préconv 15894 0 / usr / bin / preconv -e UTF-8
Homem 15896 0 / usr / bin / tbl
Homem 15897 0 / usr / bin / nroff -mandoc -rLL = 169n -rLT = 169n -Tutf8
Homem 15898 0 / usr / bin / pager -s
Nroff 15900 0 / usr / bin / locale charmap
Nroff 15901 0 / usr / bin / groff -mtty-char -Tutf8 -mandoc -rLL = 169n -rLT = 169n
Groff 15902 0 / usr / bin / troff -mtty-char -mandoc -rLL = 169n -rLT = 169n -Tutf8
Groff 15903 0 / usr / bin / grotty
[...]
2. opensnoop
Trace open () syscalls e nome do processo de impressão e detalhes do nome do caminho:
# Opensnoop
PID COMM FD ERR PATH
27159 catalina.sh 3 0 /apps/tomcat8/bin/setclasspath.sh
4057 redis-server 5 0 / proc / 4057 / stat
2360 redis-server 5 0 / proc / 2360 / stat
30668 sshd 4 0 / proc / sys / kernel / ngroups_max
30668 sshd 4 0 / etc / group
30668 sshd 4 0 /root/.ssh/authorized_keys
30668 sshd 4 0 /root/.ssh/authorized_keys
30668 sshd -1 2 / var / run / nologin
30668 sshd -1 2 / etc / nologin
30668 sshd 4 0 /etc/login.defs
30668 sshd 4 0 / etc / passwd
30668 sshd 4 0 / etc / shadow
30668 sshd 4 0 / etc / localtime
4510 snmp-pass 4 0 / proc / cpuinfo
[...]
3. ext4slower
Trace as operações lentas do ext4 que são mais lentas do que um limite fornecido (o bcc possui versões deste para btrfs, XFS e ZFS também):
# Ext4slower 1
Rastreando operações ext4 com menos de 1 ms
TIME COMM PID T BYTES OFF_KB LAT (ms) FILENAME
06:49:17 bash 3616 R 128 0 7,75 cksum
06:49:17 cksum 3616 R 39552 0 1.34 [
06:49:17 cksum 3616 R 96 0 5,36 2 a 3-2,7
06:49:17 cksum 3616 R 96 0 14,94 2to3-3.4
06:49:17 cksum 3616 R 10320 0 6.82 411toppm
06:49:17 cksum 3616 R 65536 0 4.01 a2p
06:49:17 cksum 3616 R 55400 0 8.77 ab
06:49:17 cksum 3616 R 36792 0 16.34 aclocal-1.14
06:49:17 cksum 3616 R 15008 0 19,31 acpi_listen
06:49:17 cksum 3616 R 6123 0 17.23 add-apt-repository
06:49:17 cksum 3616 R 6280 0 18.40 addpart
06:49:17 cksum 3616 R 27696 0 2.16 addr2line
06:49:17 cksum 3616 R 58080 0 10,11 ag
4. biolatência
Resumir a latência de E / S do dispositivo de bloco como um histograma a cada segundo:
# Biolatência -mT 1
Rastreamento do dispositivo do bloco I / O ... Pressione Ctrl-C para finalizar.
21:33:40
Msecs: distribuição de contagem
0 -> 1: 69 | ********************************************
2 -> 3: 16 | ********* |
4 -> 7: 6 | *** |
8 -> 15: 21 | ************ |
16 -> 31: 16 | ********* |
32 -> 63: 5 | ** |
64 -> 127: 1 | |
21:33:41
Msecs: distribuição de contagem
0 -> 1: 60 | ************************ |
2 -> 3: 100 | ***********************************************
4 -> 7: 41 | **************** |
8 -> 15: 11 | **** |
16 -> 31: 9 | *** |
32 -> 63: 6 | ** |
64 -> 127: 4 | * |
21:33:42
Msecs: distribuição de contagem
0 -> 1: 110 | *********************************************
2 -> 3: 78 | ********************************
4 -> 7: 64 | *********************** |
8 -> 15: 8 | ** |
16 -> 31: 12 | **** |
32 -> 63: 15 | ***** |
64 -> 127: 8 | ** |
[...]
5. biosnoop
E / S do dispositivo de bloco de rastreamento com detalhes de processo, disco e latência:
# Biosnoop
TEMPO (s) COMM PID DISK T SETOR BYTES LAT (ms)
0.000004001 supervisionar 1950 xvda1 W 13092560 4096 0.74
0.000178002 supervisionar 1950 xvda1 W 13092432 4096 0.61
0.001469001 supervisionar 1956 xvda1 W 13092440 4096 1.24
0.001588002 supervisionar 1956 xvda1 W 13115128 4096 1.09
1.022346001 supervisionar 1950 xvda1 W 13115272 4096 0.98
1.022568002 supervisionar 1950 xvda1 W 13188496 4096 0.93
1.023534000 supervisionar 1956 xvda1 W 13188520 4096 0.79
1.023585003 supervisionar 1956 xvda1 W 13189512 4096 0.60
2.003920000 xfsaild / md0 456 xvdc W 62901512 8192 0.23
2.003931001 xfsaild / md0 456 xvdb W 62901513 512 0.25
2.004034001 xfsaild / md0 456 xvdb W 62901520 8192 0.35
2.004042000 xfsaild / md0 456 xvdb W 63542016 4096 0.36
2.004204001 kworker / 0: 3 26040 xvdb W 41950344 65536 0.34
2.044352002 supervisionar 1950 xvda1 W 13192672 4096 0.65
[...]
6. cachestat
Mostra a proporção e o tamanho do hit / falta de cache da página e resuma todos os segundos:
# Cachestat
HITS MISSES DIRTIES READ_HIT% WRITE_HIT% BUFFERS_MB CACHED_MB
170610 41607 33 80,4% 19,6% 11 288
157693 6149 33 96,2% 3,7% 11 311
174483 20166 26 89,6% 10,4% 12 389
434778 35 40 100,0% 0,0% 12 389
435723 28 36 100,0% 0,0% 12 389
846183 83800 332534 55,2% 4,5% 13 553
96387 21 24 100,0% 0,0% 13 553
120258 29 44 99,9% 0,0% 13 553
255861 24 33 100,0% 0,0% 13 553
191388 22 32 100,0% 0,0% 13 553
[...]
7. tcpconnect
Trace TCP conexões ativas (connect ()):
# Tcpconnect
PID COMM IP SADDR DADDR DPORT
25333 recordProgra 4 127.0.0.1 127.0.0.1 28527
25338 curl 4 100.66.3.172 52.22.109.254 80
25340 curl 4 100.66.3.172 31.13.73.36 80
25342 curl 4 100.66.3.172 104.20.25.153 80
25344 curl 4 100.66.3.172 50.56.53.173 80
25365 recordProgra 4 127.0.0.1 127.0.0.1 28527
26119 ssh 6 :: 1 :: 1 22
25388 recordProgra 4 127.0.0.1 127.0.0.1 28527
25220 ssh 6 fe80: 8a3: 9dff: fed5: 6b19 fe80 :: 8a3: 9dff: fed5: 6b19 22
[...]
8. tcpaccept
Trace conexões passivas TCP (accept ()):
# Tcpaccept
PID COMM IP RADDR LADDR LPORT
2287 sshd 4 11.16.213.254 100.66.3.172 22
4057 redis-server 4 127.0.0.1 127.0.0.1 28527
4057 redis-server 4 127.0.0.1 127.0.0.1 28527
4057 redis-server 4 127.0.0.1 127.0.0.1 28527
4057 redis-server 4 127.0.0.1 127.0.0.1 28527
2287 sshd 6 :: 1 :: 1 22
4057 redis-server 4 127.0.0.1 127.0.0.1 28527
4057 redis-server 4 127.0.0.1 127.0.0.1 28527
2287 sshd 6 fe80 :: 8a3: 9dff: fed5: 6b19 fe80 :: 8a3: 9dff: fed5: 6b19 22
4057 redis-server 4 127.0.0.1 127.0.0.1 28527
[...]
9. tcpretrans
Transtornos TCP retransmissíveis e TLPs:
# Tcpretrans
TIME PID IP LADDR: LPORT T> RADDR: ESTADO DE RUA
01:55:05 0 4 10.153.223.157:22 R> 69.53.245.40:34619 ESTABELECIDO
01:55:05 0 4 10.153.223.157:22 R> 69.53.245.40:34619 ESTABELECIDO
01:55:17 0 4 10.153.223.157:22 R> 69.53.245.40:22957 ESTABELECIDO
[...]
10. gethostlatency
Mostrar latência para getaddrinfo / gethostbyname [2] chamadas de biblioteca, em todo o sistema:
# Gethostlatency
TIME PID COMM LATms HOST
06:10:24 28011 wget 90.00 www.iovisor.org
06:10:28 28127 wget 0.00 www.iovisor.org
06:10:41 28404 wget 9.00 www.netflix.com
06:10:48 28544 curl 35.00 www.netflix.com.au
06:11:10 29054 curl 31.00 www.plumgrid.com
06:11:16 29195 curl 3.00 www.facebook.com
06:11:24 25313 wget 3.00 www.usenix.org
06:11:25 29404 curl 72.00 foo
06:11:28 29475 curl 1.00 foo
[...]
11. runqlat
Mostrar a latência da fila de execução (agendador) como um histograma, a cada 5 segundos:
# Runqlat -m 5
Rastreamento da latência da fila de execução ... Pressione Ctrl-C para finalizar.
Msecs: distribuição de contagem
0 -> 1: 2085 | ********************************************
2 -> 3: 8 | |
4 -> 7: 20 | |
8 -> 15: 191 | *** |
16 -> 31: 420 | ******** |
Msecs: distribuição de contagem
0 -> 1: 1798 | **********************************************
2 -> 3: 11 | |
4 -> 7: 45 | * |
8 -> 15: 441 | ********* |
16 -> 31: 1030 | ********************** |
Msecs: distribuição de contagem
0 -> 1: 1588 | ************************************************
2 -> 3: 7 | |
4 -> 7: 49 | * |
8 -> 15: 556 | ************** |
16 -> 31: 1206 | *********************************
[...]
12. perfil
Rastros de pilha de amostra em 49 Hertz, então imprima pilhas exclusivas com o número de ocorrências vistas:
# Perfil
Amostragem em 49 Hertz de todos os tópicos pelo usuário + pilha de núcleo ... Pressione Ctrl-C para finalizar.
^ C
[...]
Ffffffff811a2eb0 find_get_entry
Ffffffff811a338d pagecache_get_page
Ffffffff811a51fa generic_file_read_iter
Ffffffff81231f30 __vfs_read
Ffffffff81233063 vfs_read
Ffffffff81234565 SyS_read
Ffffffff818739bb entry_SYSCALL_64_fastpath
00007f4757ff9680 read
- dd (14283)
29
Ffffffff8141c067 copy_page_to_iter
Ffffffff811a54e8 generic_file_read_iter
Ffffffff81231f30 __vfs_read
Ffffffff81233063 vfs_read
Ffffffff81234565 SyS_read
Ffffffff818739bb entry_SYSCALL_64_fastpath
00007f407617d680 lido
- dd (14288)
32
Ffffffff813af58c common_file_perm
Ffffffff813af6f8 apparmor_file_permission
Ffffffff8136f89b security_file_permission
Ffffffff81232f6e rw_verify_area
Ffffffff8123303e vfs_read
Ffffffff81234565 SyS_read
Ffffffff818739bb entry_SYSCALL_64_fastpath
00007f407617d680 lido
- dd (14288)
39
[...]
5.3. Ferramentas
A seção de ferramentas do
bcc no github os lista com descrições curtas. Essas ferramentas são principalmente para observabilidade e depuração de desempenho.
Existem dois tipos de ferramentas:
- Single purpose: These tools do one thing and do it well (Unix philosophy). They include execsnoop, opensnoop, ext4slower, biolatency, tcpconnect, oomkill, runqlat, etc. They should be easy to learn and use. Most of the previous examples in the General Performance Checklist were single purpose.
- Multi-tools: These are powerful tools that can do many things, provided you know which arguments and options to use. They featured in the one-liners section earlier on this page, and include trace, argdist, funccount, funclatency, and stackcount.
Each tool has three related files. Using biolatency as an example:
1/3. The tool
$ more tools/biolatency.py
#!/usr/bin/python
# @lint-avoid-python-3-compatibility-imports
#
# biolatency Summarize block device I/O latency as a histogram.
# For Linux, uses BCC, eBPF.
#
# USAGE: biolatency [-h] [-T] [-Q] [-m] [-D] [interval] [count]
#
# Copyright (c) 2015 Brendan Gregg.
# Licensed under the Apache License, Version 2.0 (the "License")
#
# 20-Sep-2015 Brendan Gregg Created this.
[...]
Tools begin with a block comment to describe basics: what the tool does, its synopsis, major change history.
2/3. An examples file
$ more tools/biolatency_example.txt
Demonstrations of biolatency, the Linux eBPF/bcc version.
biolatency traces block device I/O (disk I/O), and records the distribution
of I/O latency (time), printing this as a histogram when Ctrl-C is hit.
For example:
# ./biolatency
Tracing block device I/O... Hit Ctrl-C to end.
^C
usecs : count distribution
0 -> 1 : 0 | |
2 -> 3 : 0 | |
4 -> 7 : 0 | |
8 -> 15 : 0 | |
16 -> 31 : 0 | |
32 -> 63 : 0 | |
64 -> 127 : 1 | |
128 -> 255 : 12 |******** |
256 -> 511 : 15 |********** |
512 -> 1023 : 43 |******************************* |
1024 -> 2047 : 52 |**************************************|
2048 -> 4095 : 47 |********************************** |
4096 -> 8191 : 52 |**************************************|
8192 -> 16383 : 36 |************************** |
16384 -> 32767 : 15 |********** |
32768 -> 65535 : 2 |* |
65536 -> 131071 : 2 |* |
The latency of the disk I/O is measured from the issue to the device to its
completion. A -Q option can be used to include time queued in the kernel.
This example output shows a large mode of latency from about 128 microseconds
to about 32767 microseconds (33 milliseconds). The bulk of the I/O was
between 1 and 8 ms, which is the expected block device latency for
rotational storage devices.
The highest latency seen while tracing was between 65 and 131 milliseconds:
the last row printed, for which there were 2 I/O.
[...]
There are detailed examples files in the /tools directory, which include tool output and discussion of what it means.
3/3. A man page
$ nroff -man man/man8/biolatency.8 | more
biolatency(8) biolatency(8)
NAME
biolatency - Summarize block device I/O latency as a histogram.
SYNOPSIS
biolatency [-h] [-T] [-Q] [-m] [-D] [interval [count]]
DESCRIPTION
biolatency traces block device I/O (disk I/O), and records the distri-
bution of I/O latency (time). This is printed as a histogram either on
Ctrl-C, or after a given interval in seconds.
The latency of the disk I/O is measured from the issue to the device to
its completion. A -Q option can be used to include time queued in the
kernel.
This tool uses in-kernel eBPF maps for storing timestamps and the his-
togram, for efficiency.
This works by tracing various kernel blk_*() functions using dynamic
tracing, and will need updating to match any changes to these func-
tions.
Since this uses BPF, only the root user can use this tool.
REQUIREMENTS
CONFIG_BPF and bcc.
OPTIONS
-h Print usage message.
-T Include timestamps on output.
[...]
The man pages are the reference for what the tool does, what options it has, what the output means including column definitions, and any caveats including overhead.
5.4. Programming
Se você quiser escrever seus próprios programas bcc / eBPF, consulte o
Tutorial do desenvolvedor do PcB do
bcc . Tem mais de 15 lições que cobrem todas as funções e ressalvas que você provavelmente irá encontrar. Consulte também o
Guia de Referência do
bcc , que explica a API para eBPF C e o bcc Python. Eu criei ambos. Meu objetivo era ser prático e conciso: mostre exemplos reais e trechos de código, cubra internals e ressalvas, e faça o mais brevemente possível. Se você pressionar a página para baixo uma ou duas vezes, você atingirá o próximo título, já que deliberadamente mantive as seções baixas e evite uma parede de texto.
Para as pessoas que têm mais um interesse casual em como o bcc / BPF está programado, resumirei as coisas-chave para saber a seguir, e depois explico o código de uma ferramenta em detalhes.
5 coisas a saber
Se quiser mergulhar na codificação sem ler essas referências, aqui estão cinco coisas a serem conhecidas:
- O eBPF C está restrito : sem loops ou chamadas de função do kernel. Você só pode usar as funções bpf_ * (e alguns compilados com compilação).
- Toda a memória deve ser lida na pilha BPF primeiro antes da manipulação através do bpf_probe_read (), que faz as verificações necessárias. Se você deseja desreferenciar a-> b-> c-> d, então tente fazer isso primeiro, pois o bcc possui um reescritor que pode transformá-lo no bpf_probe_read () s necessário. Se não funcionar, adicione bpf_probe_reads () s.
- Existem 3 maneiras de produzir dados do kernel para o usuário:
- Bpf_trace_printk () . Depuração apenas, isso escreve para trace_pipe e pode colidir com outros programas e traçadores. É muito simples, então eu usei isso no início do tutorial, mas você deve usar o seguinte em vez disso:
- BPF_PERF_OUTPUT () . Uma maneira de enviar detalhes por evento para o espaço do usuário, através de uma estrutura personalizada que você define. (O programa Python atualmente precisa de uma versão ct da definição da estrutura - isso deve ser automático um dia.)
- BPF_HISTOGRAM () ou outros mapas BPF. Os mapas são um hash de valores-chave a partir do qual estruturas de dados mais avançadas podem ser criadas. Eles podem ser usados para estatísticas de resumo ou histogramas, e ler periodicamente do espaço do usuário (eficiente).
- Use pontos de rastreamento estáticos (traceponits / USDT) em vez de rastreamento dinâmico (kprobes / upsrobes) sempre que possível. Muitas vezes não é possível, mas tente. O rastreamento dinâmico é uma API instável, então seus programas serão quebrados se o código que está instrumentando mudar de uma versão para outra.
- Verifique os desenvolvimentos do bcc e os novos idiomas . Comparado com outros traçadores (DTrace / SystemTap), o bcc Python é muito mais detalhado e laborioso para codificar. Vai melhorar, então, se é um incômodo hoje, tenha em mente que ele irá melhorar. Também há esforços para criar um idioma de nível superior, que provavelmente usará o bcc (seja adicionado ao bcc como outro front-end, ou seja dependente das bibliotecas do bcc).
Exemplo de ferramenta: biolatency.py
1 #! / Usr / bin / python
2 # @ lint-avoid-python-3-compatibilidade-importações
Linha 1: somos Python. Linha 2: Eu acredito que suprime um aviso de fiapos (estes foram adicionados ao ambiente de construção de outras empresas principais).
3 #
4 # biolatência Resuma a latência de I / O do dispositivo de bloco como um histograma.
5 # Para Linux, usa BCC, eBPF.
6 #
7 # USO: biolatência [-h] [-T] [-Q] [-m] [-D] [intervalo] [contar]
8 #
9 # Direitos autorais (c) 2015 Brendan Gregg.
10 # Licenciado sob a Licença Apache, Versão 2.0 (a "Licença")
11 #
12 # 20-Set-2015 Brendan Gregg Criou isso.
Tenho um certo estilo para os meus comentários de cabeçalho. A Linha 4 nomeia a ferramenta e descreve uma única frase. A linha 5 adiciona quaisquer ressalvas: apenas para Linux, usa BCC / eBPF. Em seguida, possui uma linha de sinopse, direitos autorais e um histórico de mudanças importantes.
13
14 de __future__ import print_function
15 do BPC de importação do bcc
16 do tempo importar sono, strftime
17 importação argparse
Observe que importamos o BPF, o que usaremos para interagir com eBPF no kernel.
18
19 argumentos
20 exemplos = "" "exemplos:
21 ./biolatency # resume a latência de bloqueio I / O como um histograma
22 ./biolatência 1 10 # imprimir 1 segundo resumos, 10 vezes
23 ./biolatency -mT 1 # 1s resumos, milissegundos e timestamps
24 ./biolatency -Q # inclui o tempo de espera do SO no tempo de E / S
25 ./biolatência -D # mostra cada dispositivo de disco separadamente
26 "" "
27 parser = argparse.ArgumentParser (
28 descrição = "Resumir a latência de I / O do dispositivo de bloco como um histograma",
29 formatter_class = argparse.RawDescriptionHelpFormatter,
30 epilog = exemplos)
31 parser.add_argument ("- T", "--timestamp", action = "store_true",
32 help = "incluir timestamp na saída")
33 parser.add_argument ("- Q", "--queued", action = "store_true",
34 help = "incluir tempo de espera do sistema operacional no tempo de E / S")
35 parser.add_argument ("- m", "--milliseconds", action = "store_true",
36 help = "histograma de milissegundo")
37 parser.add_argument ("- D", "--disks", action = "store_true",
38 help = "imprimir um histograma por dispositivo de disco")
39 parser.add_argument ("interval", nargs = "?", Default = 99999999,
40 help = "intervalo de saída, em segundos")
41 parser.add_argument ("count", nargs = "?", Default = 99999999,
42 help = "número de saídas")
43 args = parser.parse_args ()
44 countdown = int (args.count)
45 debug = 0
46
As linhas 19 a 44 são processamento de argumentos. Estou usando Argparse de Python aqui.
Minha intenção é fazer deste uma ferramenta similar a Unix, algo semelhante ao vmstat / iostat, para facilitar a reconhecer e aprender. Daí o estilo de opções e argumentos, e também fazer uma coisa e fazê-lo bem. Nesse caso, mostrando a latência de E / S do disco como um histograma. Eu poderia ter adicionado um modo para despejar detalhes por evento, mas fez isso uma ferramenta separada, biosnoop.py.
Você pode estar escrevendo bcc / eBPF por outros motivos, incluindo agentes para outro software de monitoramento, e não precisa se preocupar com a interface do usuário.
47 # define o programa BPF
48 bpf_text = "" "
49 #include <uapi / linux / ptrace.h >>
50 #include <linux / blkdev.h>
51
52 typedef struct disk_key {
Disco de 53 caracteres [DISK_NAME_LEN];
Ranhura 54 u64;
55} disk_key_t;
56 BPF_HASH (início, pedido de estrutura *);
57 ARMAZENAMENTO
58
59 // bloqueio de tempo I / O
60 int trace_req_start (struct pt_regs * ctx, struct request * req)
61 {
62 u64 ts = bpf_ktime_get_ns ();
63 start.update (& req, & ts);
64 retornam 0;
65}
66
67 // saída
68 int trace_req_completion (struct pt_regs * ctx, struct request * req)
69 {
70 u64 * colher de chá, delta;
71
72 // buscar timestamp e calcular o delta
73 tsp = start.lookup (& req);
74 se (tsp == 0) {
75 retornar 0; // problema perdido
76}
77 delta = bpf_ktime_get_ns () - * tsp;
78 FATOR
79
80 // armazenar como histograma
81 LOJA
82
83 start.delete (& req);
84 retorna 0;
85}
86 "" "
O programa EBPF é declarado como um C em linha atribuído à variável bpf_text.
A linha 56 declara uma matriz de hash "início", que usa um ponteiro de solicitação de estrutura como a chave. A função trace_req_start () obtém um carimbo de data / hora usando bpf_ktime_get_ns () e, em seguida, armazena-o neste hash, digitado por * req (eu apenas estou usando esse endereço de ponteiro como UUID). A função trace_req_completion () então faz uma pesquisa no hash com o * req, para buscar a hora de início da solicitação, que é então usada para calcular o tempo delta na linha 77. A linha 83 exclui o timestamp do hash.
Os protótipos para essas funções começam com uma estrutura pt_regs * para registros e, em seguida, como muitos dos argumentos da função sondada que você deseja incluir. Eu incluí o argumento da primeira função em cada pedido de estrutura *.
Este programa também declara o armazenamento para os dados de saída e o armazena, mas há um problema: a biolatência possui uma opção -D para emitir histogramas por disco, em vez de um histograma para tudo, e isso altera o código de armazenamento. Então, este programa eBPF contém o texto STORAGE e STORE (e FACTOR), que são apenas strings que vamos pesquisar e substituir com o próximo código, dependendo das opções. Prefiro evitar código-que-escreve-código, se possível, uma vez que dificulta a depuração.
87
88 # substituições de código
89 se args.milliseconds:
90 bpf_text = bpf_text.replace ('FATOR', 'delta / = 1000000;')
91 label = "msecs"
Mais 92:
93 bpf_text = bpf_text.replace ('FACTOR', 'delta / = 1000;')
94 label = "usecs"
95 se args.disks:
96 bpf_text = bpf_text.replace ('ARMAZENAMENTO',
97 'BPF_HISTOGRAM (dist, disk_key_t);')
98 bpf_text = bpf_text.replace ('STORE',
99 'chave disk_key_t = {.slot = bpf_log2l (delta)}; '+
100 'bpf_probe_read (& key.disk, sizeof (key.disk),' +
101 'req-> rq_disk-> disk_name); Dist.incremento (chave); ')
Mais 102:
103 bpf_text = bpf_text.replace ('ARMAZENAMENTO', 'BPF_HISTOGRAMA (dist);')
104 bpf_text = bpf_text.replace ('STORE',
105 'dist.increment (bpf_log2l (delta));')
O código FACTOR apenas muda as unidades do tempo que estamos gravando, dependendo da opção -m.
A linha 95 verifica se o pedido por disco foi solicitado (-D) e, em caso afirmativo, substitui as cordas STORAGE e STORE com o código para fazer histogramas por disco. Ele usa a estrutura disk_key declarada na linha 52, que é o nome do disco e o slot (balde) no histograma power-of-2. A linha 99 leva o tempo delta e converte-o no índice de slot power-of-2 usando a função helper bpf_log2l (). As linhas 100 e 101 obtêm o nome do disco através de bpf_probe_read (), que é como todos os dados são copiados na pilha da BPF para operação. A Linha 101 inclui muitas dereferências: req-> rq_disk, rq_disk-> disk_name: o reescritor do bcc também transformou estas em bpf_probe_read () s.
As linhas 103 a 105 lidam com o caso do histograma único (não por disco). Um histograma é declarado chamado "dist" usando a macro BPF_HISTOGRAM. O slot (balde) é encontrado usando a função helper bpf_log2l () e, em seguida, incrementado no histograma.
Este exemplo é um pouco corajoso, o que é bom (realista) e ruim (intimidante). Veja o tutorial que liguei anteriormente para exemplos mais simples.
106 se debug:
107 imprimir (bpf_text)
Como eu tenho código que escreve código, preciso de uma maneira de depurar o resultado final. Se o debug estiver configurado, imprima.
108
109 # load BPF program
110 b = BPF (texto = bpf_text)
111 se args.queued:
112 b.attach_kprobe (evento = "blk_account_io_start", fn_name = "trace_req_start")
Mais 113:
114 b.attach_kprobe (evento = "blk_start_request", fn_name = "trace_req_start")
115 b.attach_kprobe (evento = "blk_mq_start_request", fn_name = "trace_req_start")
116 b.attach_kprobe (evento = "blk_account_io_completion",
117 fn_name = "trace_req_completion")
118
A linha 110 carrega o programa eBPF.
Uma vez que este programa foi escrito antes do EBPF possuir suporte para tracepoint, escrevi para usar kprobes (rastreamento dinâmico do kernel). Ele deve ser reescrito para usar pontos de rastreamento, pois eles são uma API estável, embora isso também requer uma versão do kernel posterior (Linux 4.7+).
Biolatency.py tem uma opção -Q para o tempo incluído na fila no kernel. Podemos ver como é implementado neste código. Se estiver configurado, a linha 112 atribui a nossa função eBPF trace_req_start () com um kprobe na função de kernel blk_account_io_start (), que rastreia a solicitação quando está na fila no kernel. Se não for definido, lnes 114 e 115 anexam nossa função eBPF a diferentes funções do kernel, que é quando o disco I / O é emitido (pode ser um desses). Isso só funciona porque o primeiro argumento para qualquer uma dessas funções de kernels é o mesmo: solicitação de estrutura *. Se seus argumentos fossem diferentes, eu precisaria de funções eBPF separadas para cada um para lidar com isso.
119 imprimir ("Detecção de bloqueio do dispositivo I / O ... Pressione Ctrl-C para finalizar.")
120
121 # saída
122 saindo = 0 se args.interval else 1
123 dist = b.get_table ("dist")
A linha 123 busca o histograma "dist" que foi declarado e preenchido pelo código STORAGE / STORE.
124 enquanto (1):
125:
126 sleep (int (args.interval))
127, exceto KeyboardInterrupt:
128 saindo = 1
129
130 imprimir ()
131 if args.timestamp:
132 imprimir ("% - 8s \ n"% strftime ("% H:% M:% S"), final = "")
133
134 dist.print_log2_hist (rótulo, "disco")
135 dist.clear ()
136
Contagem regressiva 137 - = 1
138 se sair ou contagem regressiva == 0:
139 exit ()
Isso tem lógica para imprimir todos os intervalos, um certo número de vezes (contagem regressiva). Linhas 131 e 132 imprime um carimbo de data / hora se a opção -T foi usada.
A linha 134 imprime o histograma ou histogramas se estiver fazendo por disco. O primeiro argumento é a variável de rótulo, que contém "usecs" ou "msecs", e decora a coluna de valores na saída. O segundo argumento é rótulos da chave secundária, se dist tiver histogramas por disco. Como print_log2_hist () pode identificar se este é um histograma único ou tem uma chave secundária, vou deixar um exercício aventureiro no spelunking de código dos componentes internos do eBPF e bcc.
A linha 135 limpa o histograma, pronto para o próximo intervalo.
Aqui está uma amostra de saída:
# Biolatência
Rastreamento do dispositivo do bloco I / O ... Pressione Ctrl-C para finalizar.
^ C
Usecs: distribuição de contagem
0 -> 1: 0 | |
2 -> 3: 0 | |
4 -> 7: 0 | |
8 -> 15: 0 | |
16 -> 31: 0 | |
32 -> 63: 0 | |
64 -> 127: 1 | |
128 -> 255: 12 | ******** |
256 -> 511: 15 | ********** |
512 -> 1023: 43 | ******************************* |
1024 -> 2047: 52 | ***************************************
2048 -> 4095: 47 | *************************************
4096 -> 8191: 52 | ****************************************
8192 -> 16383: 36 | *******************************
16384 -> 32767: 15 | ********** |
32768 -> 65535: 2 | * |
65536 -> 131071: 2 | * |
Saída por disco:
# Biolatência -D
Rastreamento do dispositivo do bloco I / O ... Pressione Ctrl-C para finalizar.
^ C
Disk = 'xvdb'
Usecs: distribuição de contagem
0 -> 1: 0 | |
2 -> 3: 0 | |
4 -> 7: 0 | |
8 -> 15: 0 | |
16 -> 31: 0 | |
32 -> 63: 0 | |
64 -> 127: 18 | **** |
128 -> 255: 167 | **********************************************
256 -> 511: 90 | ********************* |
Disk = 'xvdc'
Usecs: distribuição de contagem
0 -> 1: 0 | |
2 -> 3: 0 | |
4 -> 7: 0 | |
8 -> 15: 0 | |
16 -> 31: 0 | |
32 -> 63: 0 | |
64 -> 127: 22 | **** |
128 -> 255: 179 | **************************************************************************
256 -> 511: 88 | ******************* |
Disco = 'xvda1'
Usecs: distribuição de contagem
0 -> 1: 0 | |
2 -> 3: 0 | |
4 -> 7: 0 | |
8 -> 15: 0 | |
16 -> 31: 0 | |
32 -> 63: 0 | |
64 -> 127: 0 | |
128 -> 255: 0 | |
256 -> 511: 167 | **********************************************
512 -> 1023: 44 | ********** |
1024 -> 2047: 9 | ** |
2048 -> 4095: 4 | |
4096 -> 8191: 34 | ******** |
8192 -> 16383: 44 | ********** |
16384 -> 32767: 33 | ******* |
32768 -> 65535: 1 | |
65536 -> 131071: 1 | |
A partir da saída, podemos ver que xvdb e xvdc possuem histogramas de latência semelhantes, enquanto que xvda1 é bastante diferente e bimodal, com um modo de latência maior entre 4 e 32 milissegundos.
6. perf
EBPF também pode ser usado a partir do comando perf de Linux (aka perf_events) no Linux 4.4 e mais recente. Quanto mais novo for o melhor, como o suporte perf / BPF continua melhorando com cada versão. Eu já forneci um exemplo até agora na minha página
perf :
perf eBPF .
7. Referências
8. Agradecimentos
Muitas pessoas trabalharam em traçadores e contribuíram de maneiras diferentes ao longo dos anos para chegar onde estamos hoje, incluindo aqueles que trabalharam nas estruturas Linux que o bcc / eBPF usa: pontos de rastreamento, kprobes, arranha-céus, ftrace e perf_events. Os contribuidores mais recentes incluem Alexei Starovoitov, que liderou o desenvolvimento do eBPF, e Brenden Blanco, que liderou o desenvolvimento do bcc. Muitas das ferramentas de bcc de propósito único foram escritas por mim (execsnoop, opensnoop, biolatency, ext4slower, tcpconnect, gethostlatency, etc.) e duas das mais importantes ferramentas múltiplas (trace e argdist) foram escritas por Sasha Goldshtein. Eu escrevi uma lista mais longa de agradecimentos no final
desta publicação . Obrigado a todos!
9. Atualizações
Este é principalmente o meu próprio trabalho, apenas porque eu tenho meus próprios URLs à disposição para listar. Eu consertarei isso e continuarei adicionando postagens externas.
2015
2016
2017
Criado: 28 de dezembro de 2016
- Linux bcc / BPF Run Queue (Scheduler) latência
- Linux bcc / BPF Node.js rastreamento USDT
- Linux bcc tcptop
- Profiler eficiente baseado em BPF do Linux 4.9
- DTrace para Linux 2016
- Ferramentas de rastreamento do Linux 4.x: usando superpoderes do BPF
- Linux bcc / BPF tcplife: TCP Lifespans
2017
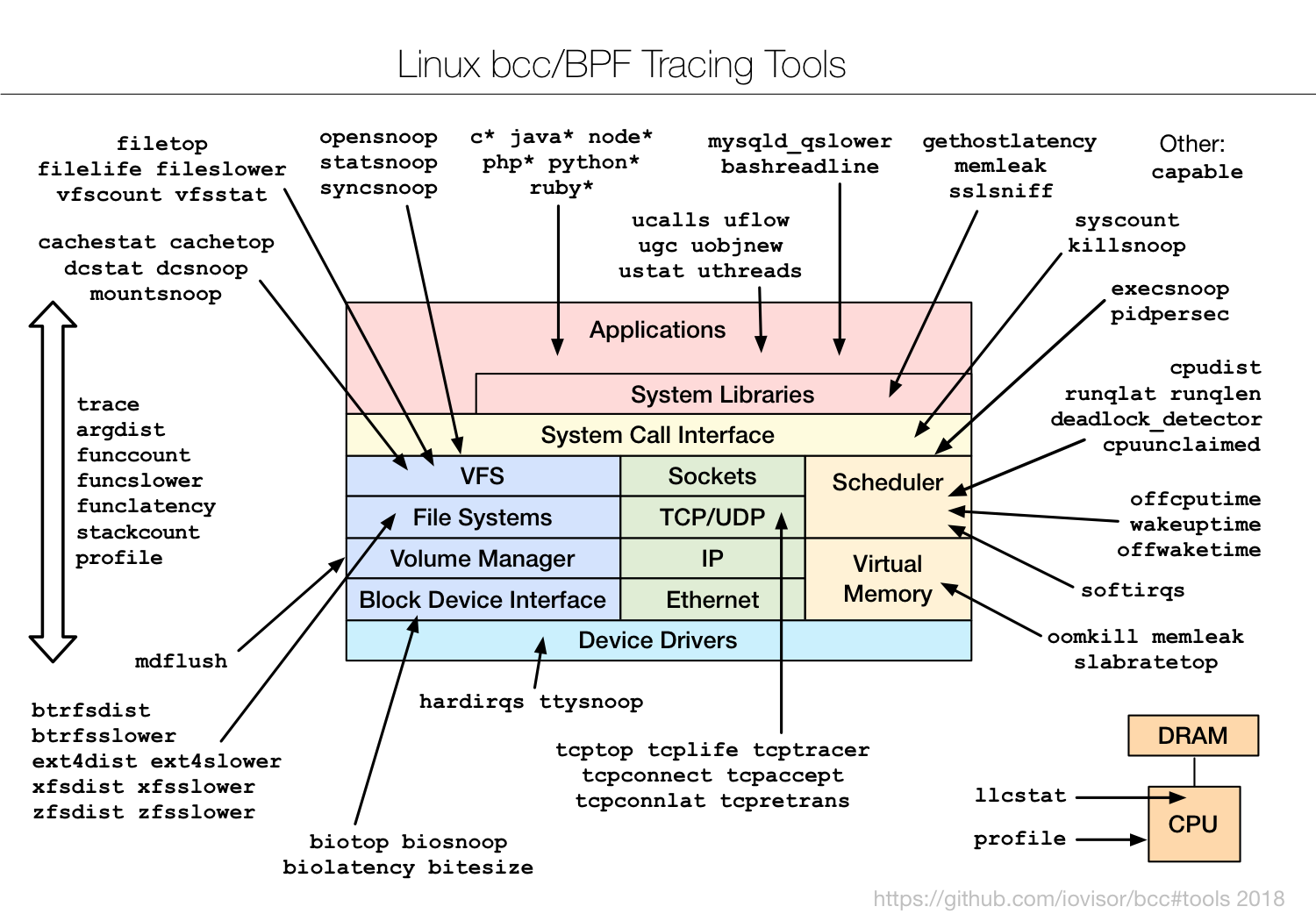

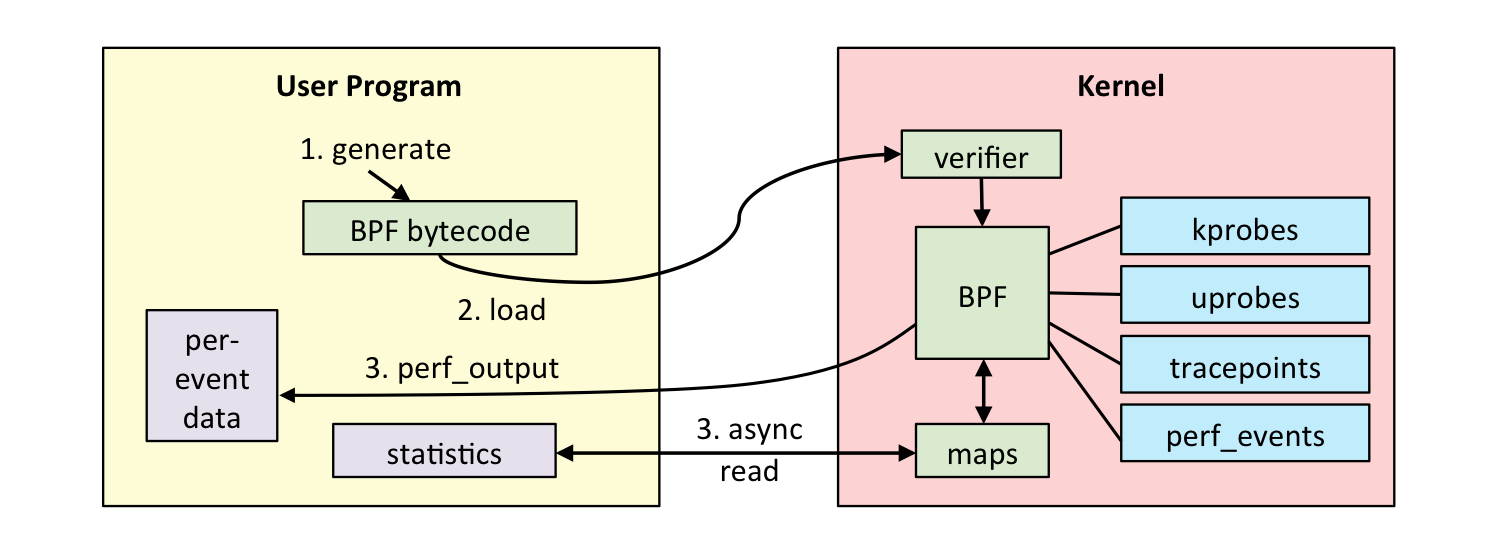
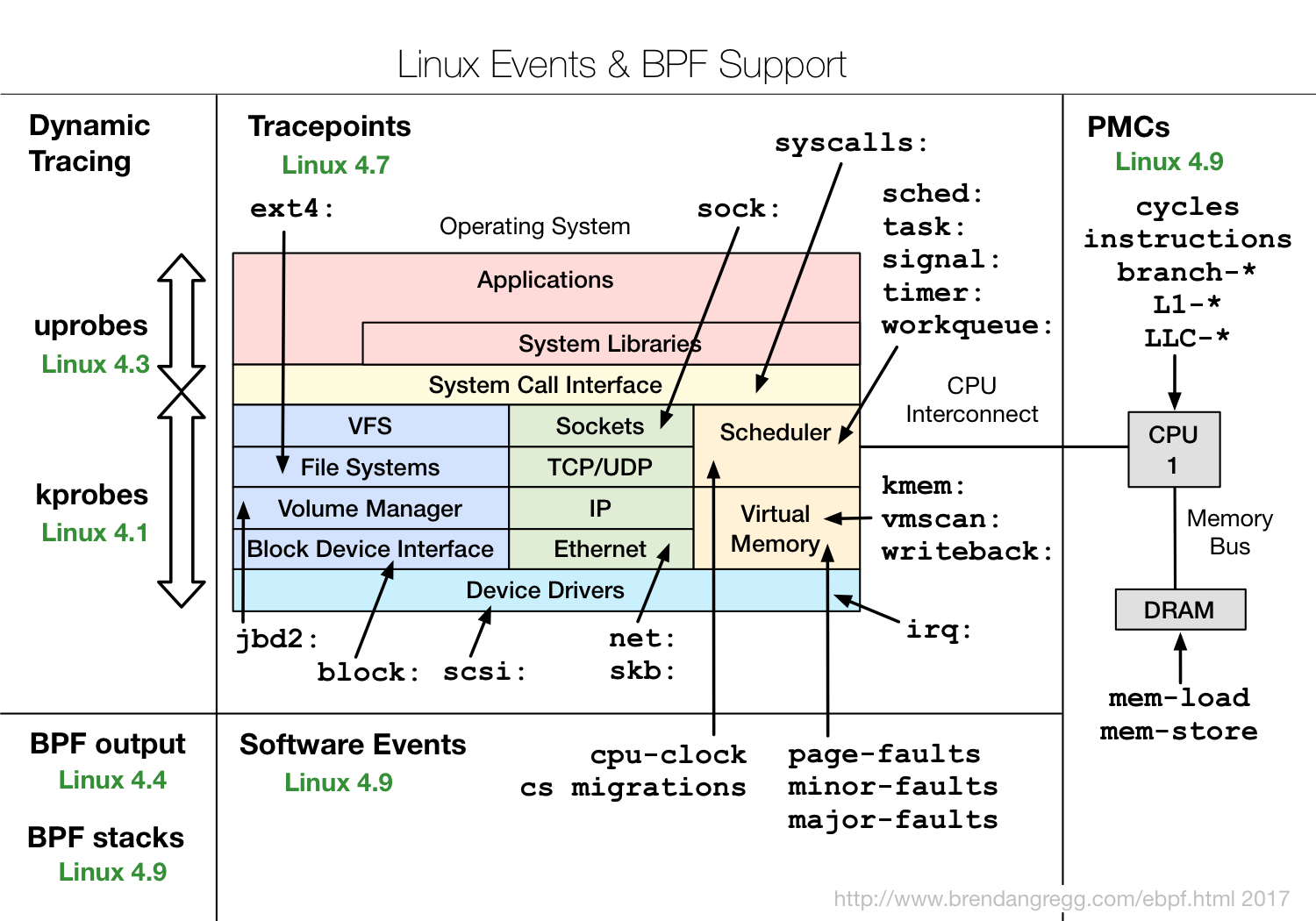








Comentários
Postar um comentário